在学习一门新语言时,想必我们都是”Hello World”程序开始,类似地,分布式计算框架的一个典型实例就是WordCount程序,接触过Hadoop的人肯定都知道用MapReduce实现WordCount,当前内存分布式计算框架Spark因为其计算速度之快,并且可以部署到Hadoop YARN中运行,已经受到各大公司的青睐,Spark社区提供了一些编译好的jar包,但是其中没有适配Hadoop-2.2.0的jar包,为了避免版本问题,需要自己编译指定hadoop版本的Spark jar包。下面介绍如何编译Spark源码并在YARN上运行WordCount程序。
Spark是由Scala编写的,虽然我们也可以通过Spark的Java或Python接口来编写应用程序,但是为了能更好的学习Spark,建议采用Scala来编写应用程序,Scala是一种函数式编程语言,其简洁和优雅的编程风格相信在不久后会让你喜欢上它的。之前我已经安装配置好Hadoop环境,请参考本站前面的一篇文章”CentOS下Hadoop-2.2.0集群安装配置“,下面我们来安装Scala编译环境。
Scala安装配置
去Scala官网下载Scala,我下载的是Scala-2.10.4(因为官方提供的spark-1.1.0编译好的jar包都是基于scala-2.10.4编译的),将下载后的软件包解压到用户根目录,并配置好环境变量。
[hadoop@master ~]$ tar zxvf scala-2.10.4.tgz
[hadoop@master ~]$ vim ~/.bash_profile
#添加Scala环境变量
export SCALA_HOME=$HOME/scala-2.10.4
export PATH=$SCALA_HOME/bin:$PATH
Spark安装配置
去Spark社区下载Spark源码,我下载的是spark-1.1.0版本,解压,并进入源码根目录,执行以下命令编译:
[hadoop@master ~]$ tar zxvf spark-1.1.0.tgz
[hadoop@master ~]$ cd spark-1.1.0
[hadoop@master ~]$ sbt/sbt assembly -Pyarn -Phadoop-2.2 -Pspark-ganglia-lgpl -Pkinesis-asl -Phive
值得说明的是,我指定编译规则是集成hadoop2.2的,以便与我的Hadoop环境适配,这里需要等待漫长的编译过程…中途要下载大量的依赖包。编译完成后,可以在目录assembly中找到编译打包好的jar包:
[hadoop@master scala-2.10]$ ls
spark-assembly-1.1.0-hadoop2.2.0.jar
[hadoop@master scala-2.10]$ pwd
/home/hadoop/spark-1.1.0/assembly/target/scala-2.10
下面我们配置Spark的环境变量:
[hadoop@master ~]$ vim ~/.bash_profile
#添加Spark环境变量
export SPARK_HOME=$HOME/spark-1.1.0
export PATH=$SPARK_HOME/bin:$PATH
如何让Spark能知道我们的YARN在哪呢,这里需要在Spark配置文件中指定一下YARN的位置:
[hadoop@master ~]$ cd $SPARK_HOME/conf/
[hadoop@master conf]$ cp spark-env.sh.template spark-env.sh
[hadoop@master conf]$ vim spark-env.sh
#添加如下两行,指定你的java和yarn的位置
export JAVA_HOME=/home/hadoop/jdk1.7.0_40/
export YARN_CONF_DIR=/home/hadoop/hadoop-2.2.0/etc/hadoop/
环境都准备好了,下面我们介绍如何构建Spark WordCount项目,并将其部署到YARN上运行。
构建WordCount项目
这里采用sbt的方式来构建项目,需要满足sbt的项目目录结构(其中target目录是编译后自动生成的):
|--build.sbt
|--lib
|--project
|--src
| |--main
| | |--scala
| |--test
| |--scala
|--sbt
|--target
先创建出项目的目录结构,并从spark目录中拷贝sbt构建工具和前面编译好的jar包:
[hadoop@master ~]$ mkdir -p spark-wordcount/lib
[hadoop@master ~]$ mkdir -p spark-wordcount/project
[hadoop@master ~]$ mkdir -p spark-wordcount/src/main/scala
[hadoop@master ~]$ mkdir -p spark-wordcount/src/test/scala
[hadoop@master ~]$ cp -R $SPARK_HOME/sbt spark-wordcount/
[hadoop@master ~]$ cp -R $SPARK_HOME/assembly/target/scala-2.10/spark-assembly-1.1.0-hadoop2.2.0.jar spark-wordcount/lib/
创建sbt项目构建文件build.sbt,该文件指定项目名、scala版本以及声明依赖,但是本实例先不加入依赖,直接将依赖的jar包放到项目的lib目录下:
[hadoop@master ~]$ cd spark-wordcount
[hadoop@master spark-wordcount]$ vim build.sbt
name := "WordCount"
[空行]
version := "1.0.0"
[空行]
scalaVersion := "2.10.4"
在project目录下新建文件build.properties,里面指定sbt的版本:
[hadoop@master project]$ vim build.properties
sbt.version=0.13.5
到这里,WordCount项目的准备工作都已做好了,下面我们用scala来编写Spark WordCount程序,在目录src/main/scala/目录下新建文件WordCount.scala:
1 | import org.apache.spark._ |
代码编写完毕后,开始编译打包,在项目根目录下用sbt编译打包:
[hadoop@master spark-wordcount]$ sbt/sbt clean compile package
编译完成后,我们能看到会多出一个target目录,里面就包括了编译后的.class文件和打好的jar包:
[hadoop@master spark-wordcount]$ sbt/sbt clean compile package
[hadoop@master spark-wordcount]$ ls target/scala-2.10/
classes wordcount_2.10-1.0.0.jar
在YARN上运行WordCount
在hdfs上首先上传一些待处理的文本:
[hadoop@master spark-wordcount]$ $HADOOP_HOME/bin/hdfs dfs -put ~/test.txt input
编写如下启动脚本,将Spark WordCount提交到YARN上运行:
1 | !/usr/bin/env bash |
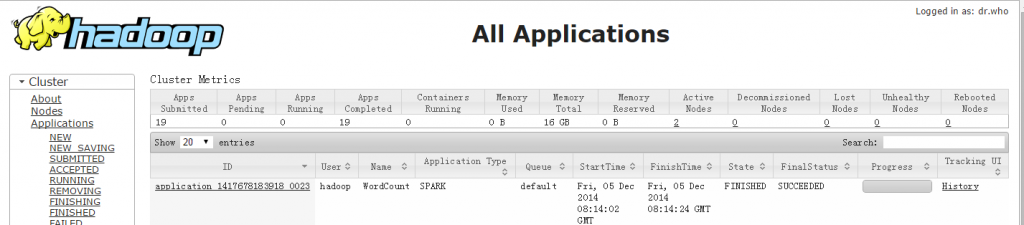
这里采用的是yarn-cluster部署模式,num-executors指定启动的executor数量,driver-memory指定drive端所需内存大小,executor-memory指定executor所需内存大小,executor-cores指定每个executor使用的内核数。运行如上脚本后,打开Hadoop的web页面可以看到运行正常,如下图所示:
转载请注明出处,本文永久链接:https://sharkdtu.github.io/posts/spark-build.html

