Lance 是一种专为向量和多模态数据设计的数据存储格式,其内置高效索引,支持快速随机访问、向量检索、全文检索等。它包含两种格式:列式 File Format(对标 Parquet) 和 Table Format(对标 Iceberg),其中 Table Format 是在 File Format 基础上组织的数据集。
注:本文大部分内容直接翻译自参考资料(最新到 Lance Format v2.1),夹带这一些自己的个人理解,如有错误,敬请指正。
1. 背景
AI 应用正迎来爆发式增长,然而现有的数据湖存储方案(如 Iceberg/Parquet)难以满足 AI Workloads(如 AI 训练/推理、Agent 开发等)的开发需求,主要存在以下几个问题:
- 缺少对非结构化数据、多模态数据的支持
- 难以实现高效的随机访问能力
- 缺少原生的向量检索和全文检索等查询功能
Lance 的设计目标就是解决上述问题。
2. 传统列式存储的问题(以Parquet为例)
首先简单介绍 Parquet 列式存储格式的布局,如下图所示。
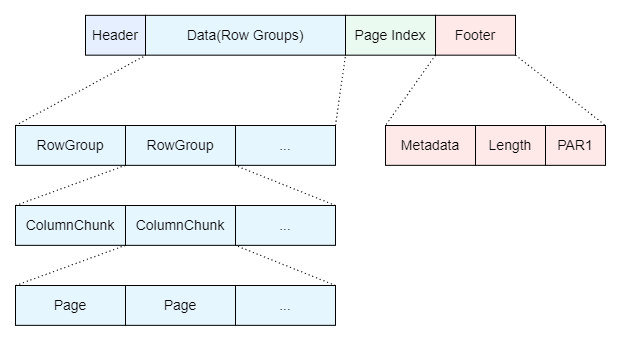
- Header:只有4个字节,本质是一个 magic number,通常为 PAR1。
- RowGroup:如果把一个 Parquet 文件看成一张表,那么对这张表按固定大小水平切分的部分就是 RowGroup,在分布式存储系统中,文件通常会被分块跨机器多副本存储,以提升存储可靠性,那么一个 RowGroup 就可以作为一个 Block,这样可以提升分布式并行读取效率。
- ColumnChunk:RowGroup 内部会按列垂直切分,每一列的数据分片就是一个个 ColumnChunk,这也是列式存储的关键,有益于高效压缩和按列读取。
- Page:ColumnChunk 内部还会继续按固定大小水平切分,形成一个个 Page,主要是为了让数据访问的粒度足够小,Page 作为最小的存储、编码、压缩单元。
- Page Index:为了快速索引指定 Page,达到快速读取的目的,例如谓词下推就是一种查询优化技术,通过查询条件,缩小读取范围,可有效减少数据的读取和传输量,目前仅支持 min-max、bloomfilter 索引。
- Footer:存储文件元数据信息,包含了 Schema 以及 RowGroup/ColumnChunk 的位置信息以及统计信息。数据读取首先读取 Footer,再索引到指定位置读取数据。之所以把元数据信息放 Footer,主要是为了让文件写入的操作在一趟内完成,因为写完数据后,位置信息和统计信息都有了,直接追加到文件尾部即可。
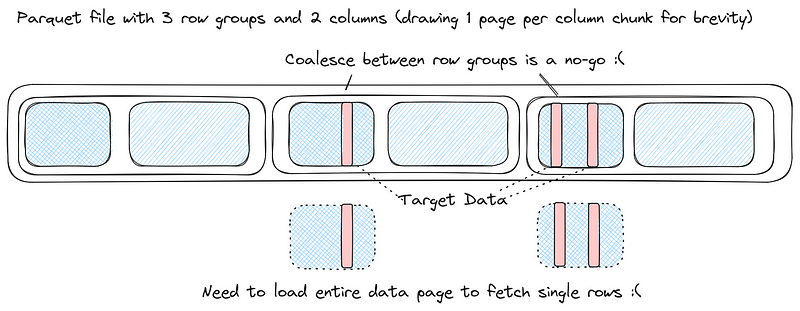
2.1. 点查性能差
按主键列查询(写入时,该列有 Page 索引),Parquet 最多只支持到 Page 级别索引,查询的数据可能也会分散在多个 RowGroup(如下图所示),无法快速定位到单条数据。
2.2. 列大小差距大时,访问性能不佳
在 ML/AI 场景,Embeddings、Tensors、文本、图片、音视频等二进制列通常是宽列,在数据多列且大小不均的情况下,选择合适的 RowGroup 大小比较困难,且会影响读取性能。
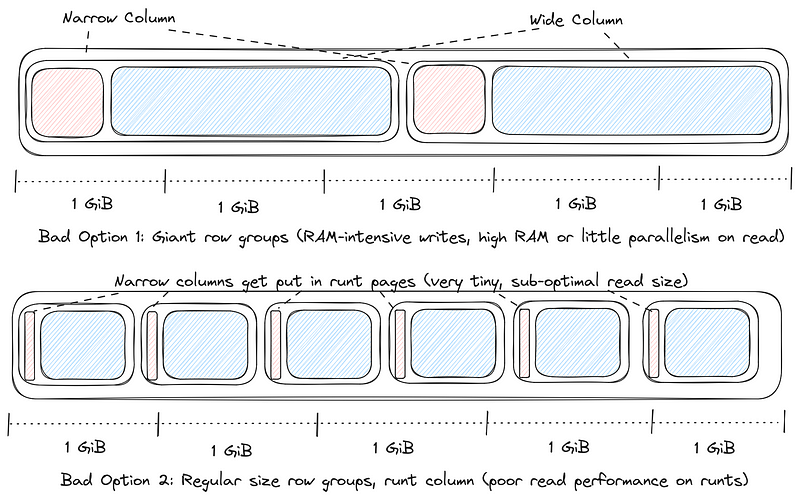
如上图所示:
- 设置过大 row group size 时,row group 数量就更少,数据读写需要更多内存,读取并行度也会降低
- 设置常规 row group size 时,因为宽列的存在,一个 row group 没几条数据,如果访问比较小的列,那么需要加载更多的 row group,带来更多的 io,影响读取性能
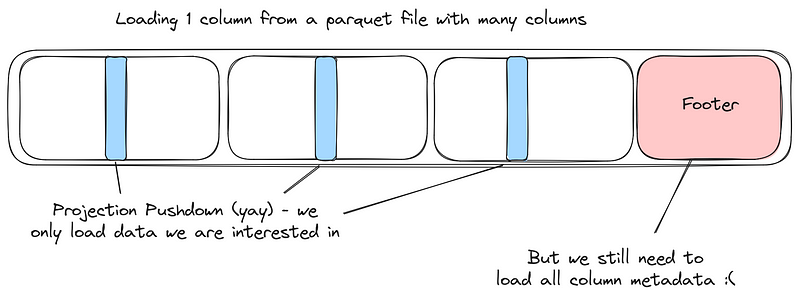
2.3. 列非常多的情况下,元数据开销大
不少业务场景下,列非常多,尤其是 ML 场景,如果只访问部分列,Parquet 也需要加载全部 Footer 元数据信息,这对低延迟工作负载来说是一笔不小的开支,如果并行读多个文件,缓存多个文件的元数据会占用大量内存。
2.4. 其他
- 仅支持通用编码类型,对特定数据的编码支持相对较少(无法自定义编码)
- 缺乏对特定类型(例如 embedings、tensors,、blob 等)的原生支持
3. Lance File Format
Lance v2 文件,列式存储格式的布局为 Pages - Column Descriptors - Footer,如下图所示:
- Data Pages:由一系列的 Buffers 组成,Buffer 主要为编码后的数据或元数据
- Column Descriptors:由三部分组成
- Column Metadata:列元数据块,包含每列的页块、编码等信息
- Column Metadata Offset Table:列元数据索引,指向列元数据块
- Global Buffers Offset Table:全局元数据索引,指向全局元数据,例如全局字典
- Footer:元数据的索引,指向除 Data Pages 以外的部分,占用固定大小存储(相比Parquet而言,Lance Footer足够小)

3.1. 无 RowGroup 设计
RowGroup 最初是为了分布式并行 scan 而设计(大文件分块存储,并行处理),Lance 设计者认为,拆解到多文件同样能达到分布式并行处理的能力(类似一个文件一个 RowGroup),所以直接抛弃 RowGroup 的设计,这样可以不用为设置多大的 RowGroup 而烦恼。
在 Lance 文件中,不再按 RowGroup 水平切分,直接将每个列切分成多个 Pages,Page 的大小最好等于存储系统的最小读写单位(例如 S3 是 8MB),这样读写过程中,正好是按 Page 大小去读写存储系统。举个例子,假设需要写10M (1KW) 个记录,Page 大小使用 8MB,其中一列为 8 字节的 double,一列为 bool,那么 double 列需要写 10 个 Pages,bool 列只需要写 1 个 Page(一个 bit 存储一个 bool,1 个 Page 可以容纳 64M 个 bool)。

在文件 Scan 方面,Lance 这种无 RowGroup 的设计效率也更高,甚至在文件大小是 Parquet 的 2-3 倍时也能超越 Parquet。延续上面的例子,如果需要将 double 和 bool 列的数据全部读出来处理,首先,将读取 double 列的第一个 Page 和 bool 列的第一个 Page(只有一个),这两个 8MB Page 读取完成后,就可以得到 1M 个 double 值,10M 个 bool 值,逻辑上可以解码 1M 条记录,假设一次解码处理 10K 条记录,那么这读出来的两个 Page 就需要 100 个解码处理任务,在这些解码任务运行的同时,可以并行去读取 double 列剩余的 Pages,做到 IO 与解码计算解耦分离。
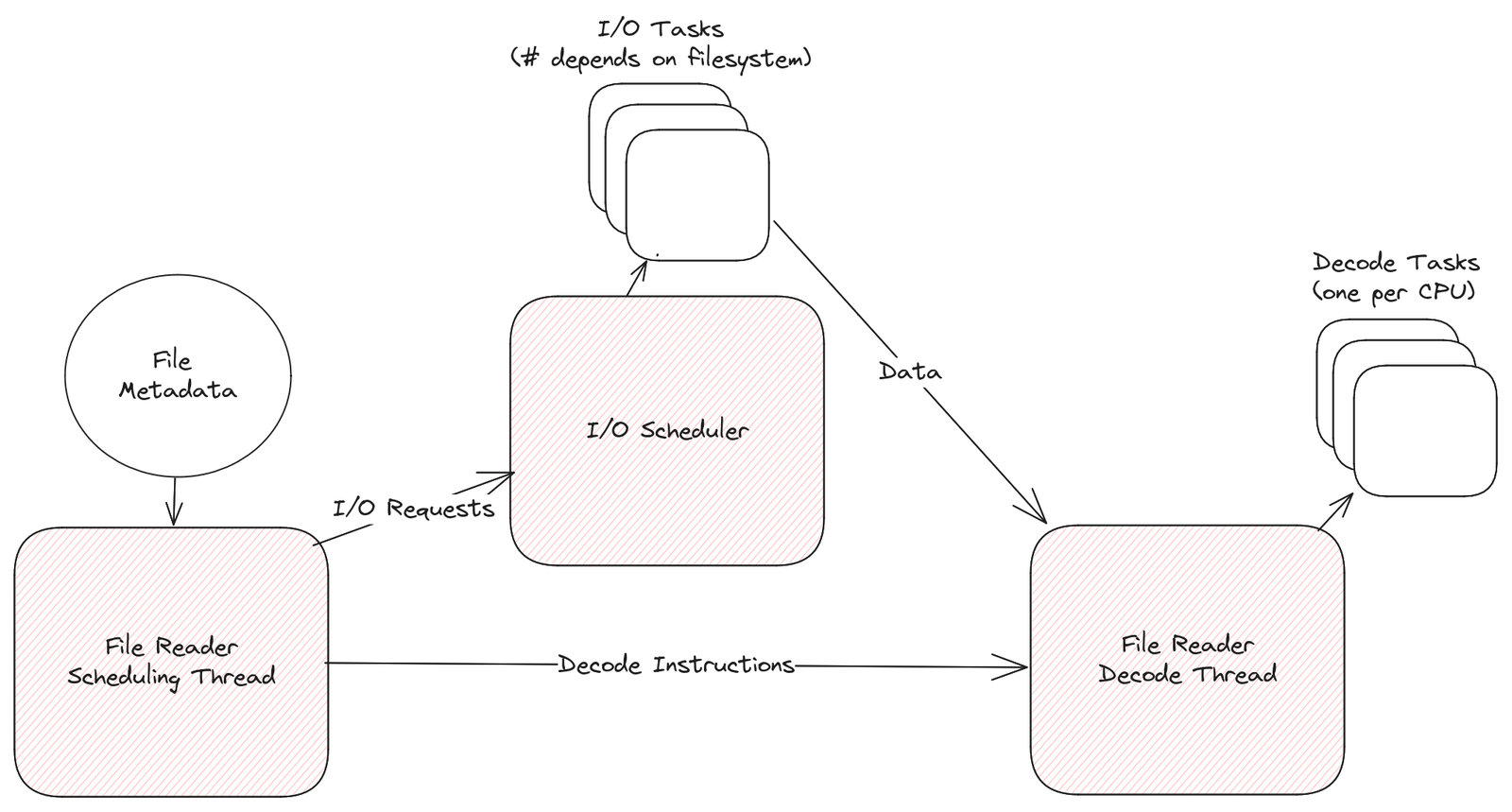
然而在传统的 Parquet 文件读取时,解码计算与 IO 是耦合的,例如读取并行度为 M(有 M 个 RowGroup),每条记录要读 N 列,那么 IO 请求并行度一定是 M*N,解码计算与 IO 存在相互制约,影响读取吞吐。
3.2. 编码作为扩展
Lance 本身没有类型系统,每个页块(Page)包含多个 Buffers,当然,文件读写时需要将这些 Buffers 跟某种类型系统对应起来,Lance 使用 Arrow 类型系统(列式内存格式),这样做的好处是不用设计一种新的类型系统,尽可能使格式规范简单明了。
既然没有设计新的类型系统,所以 Lance 不限定编码格式(如字典编码、Bitpacking、Delta 编码等),完全由扩展处理,文件读写实现不需要事先知道任何类型的编码,数据生产者选择使用哪种编码以及编码工作的细节由插件决定,如果要使用新的编码,不需要调整文件存储布局和读写实现。
具体做法是将编码描述直接存储到元数据块中,可以是全局编码、列级别编码、页级别的编码,如果开发某种新的编码,那么只需要发布一个 .proto 文件来描述编码的方式,并编写一个编码器/解码器,如果用户试图读取用这种编码编写的文件,而读取时不支持这种编码,那么就会收到一个有用的错误信息 “此文件使用 X 编码,未配置解码器”。
3.3. 存储灵活性
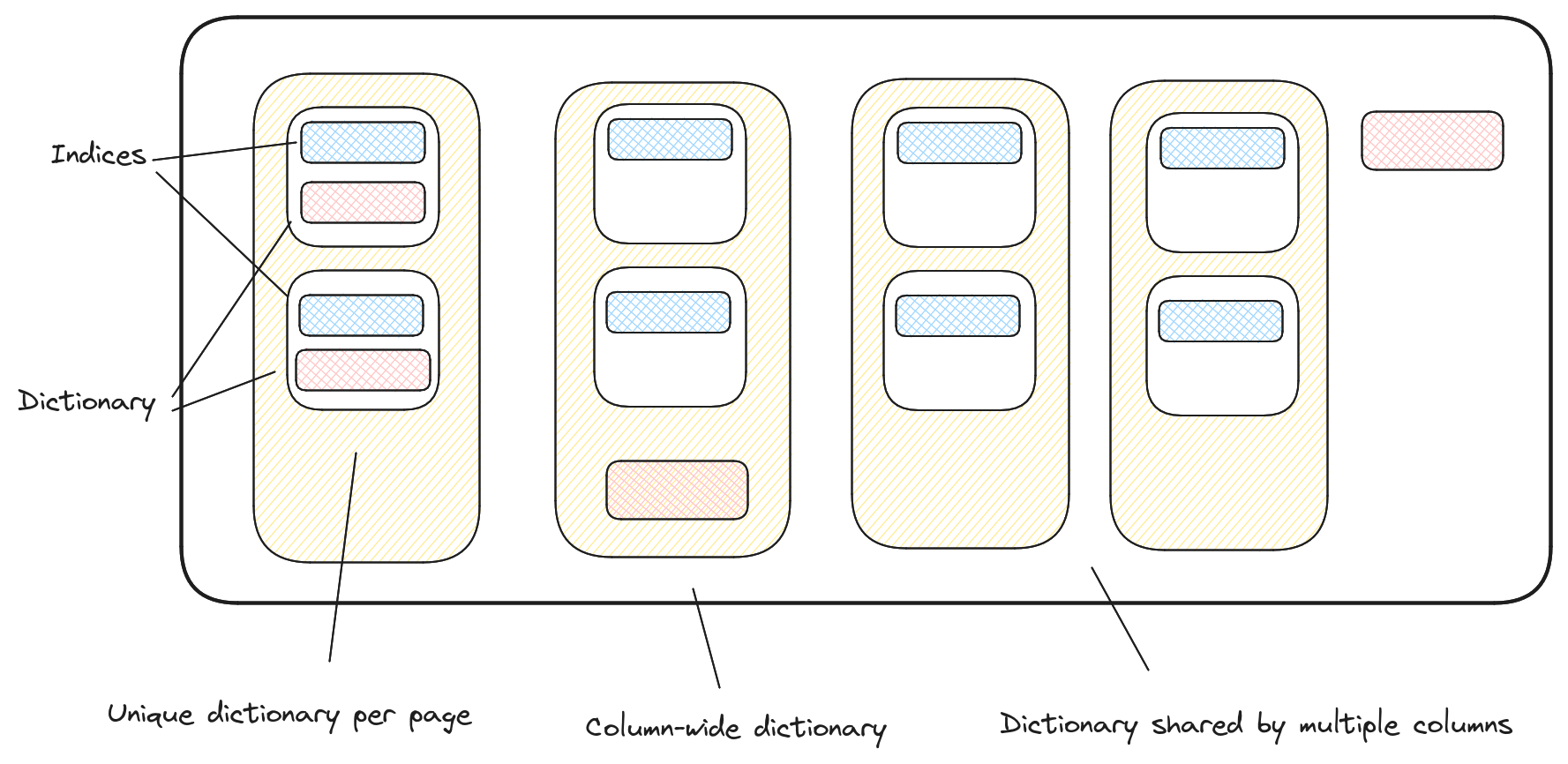
如下图所示,相同列的 Pages 不一定要连续存储 ,不同列的 Pages 个数可以不一样,不同 Page 的 item 条数可以不一样,甚至不同列的 item 条数也可以不一样,存储非常灵活紧凑。

如下图,Lance 文件布局,每一列的元数据都在一个完全独立的块中,这意味着可以读取指定列而无需读取其他列的元数据,所以可以有数十万甚至数百万列,都不会影响性能。因为 Footer 足够小,通过 Footer 很快找到指定列的索引进而定位指定列。
值得强调的是,Lance 文件中的 Data Pages 部分不仅仅有数据,也可能有元数据。实际存储时,数据与元数据可以流动存储,Writer 在写入时可以选择最合适的位置写入编码后的数据或元数据。举个例子,字典编码的列,如果某一列不同 Page 之间存在差异,那么 Writer 应将字典作为 Page 数据写入,如果某一列的字典可以预先提供,那么 Writer 应将字典作为列元数据写入,如果多个列有共同的字典,那么 Writer 应将字典作为全局元数据写入。类似地,统计信息(例如 zone map,min/max/null)也可以按类似方式流动存储,一般来说,统计信息通常作为索引,所以扩展增加新的索引变得非常容易,这在 Parquet 中是做不到的。
3.4. 随机访问与扫描访问权衡
如前文所述,Lance 没有固定的编码,使用 Arrow 类型系统,假如没有编码,则是直接使用 Arrow IPC 列式格式存储,这样会因为编码压缩不足,导致存储文件非常大,扫描访问性能差,对于复杂类型的随机访问,如 list
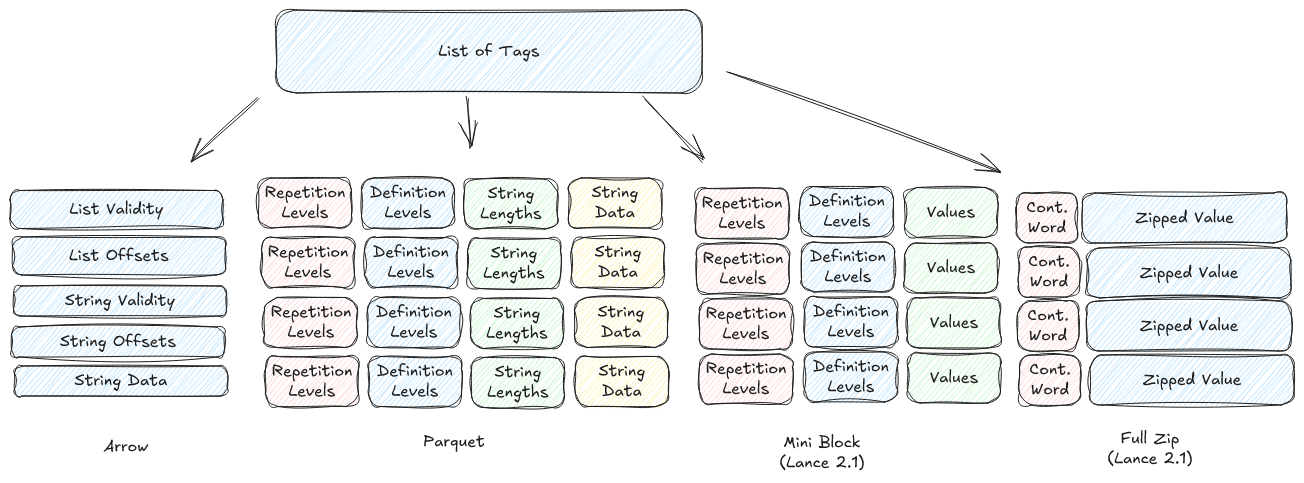
为了权衡随机访问和扫描访问性能,Lance v2.1 设计了结构化编码,对于简单类型的随机访问,最多需要 1 次 IOP,对于任意复杂类型(包括任意嵌套)的随机访问,最多需要 2 次 IOP。具体地,写入时会根据值平均大小等启发式规则在两种结构化编码中二选其一:
- Full Zip 编码:适合“大/长/嵌套”的值(128 字节及以上),将 repetition level 和 definition level 编码为 1~4 字节的控制字,跟 value-buffer 粘一起存储,写入时会新增一个索引,指向每个值对应的控制字,那么随机访问时,先通过索引找到指定行的控制字,再解码对应的值,总共需 2 次 IOP,优点是比 Arrow IPC 列式格式有更高的压缩比,又能将随机访问的 IOP 控制在 2 次以内,但是相比 Parquet,需要增加索引元数据,会额外占用存储,牺牲一点扫描性能。
- Mini-block 编码:适合“小/短”的值,类似 Parquet 的做法,将 repetition/definition levels、values 切成小 chunk(4–8 KiB),然后通过非透明压缩存储,随机访问需要读取整个 chunk(通常只需一次 IOP),因为数据类型足够小,可以接受一定量的读取放大,优点是不损失扫描性能。
4. Lance Table Format
一份数据集不可能全部存储到一个 Lance 文件中,为此,Lance 团队在 File Format 基础上设计了 Table Format,用于存储数据集。以下是 Lance Table(也称之为 Lance Dataset) 的物理存储布局:
1 | /path/to/dataset: |
- data:数据目录,里面包括多个 lance 数据文件
- _versions:清单(元数据)目录,一个版本一个,方便版本管理与历史追溯
- _indices:二级索引目录(清单文件为一级索引),每个子目录为一个索引
- _deletions:删除文件目录,每个文件保存了已经删除的行号信息
如前文所述,Lance File Format 它不内置类型,不绑定编码,所以在 Lance Dataset 中,这些信息可以放到清单(Manifest)文件中。
另外,统计值(如 zone-map)这类“索引性”数据也可以放到 Lance 文件外,这样可以实现动态索引功能(增加索引、重建索引等),而不用重写主数据文件。
整体上来说,Lance Table Format 是建立在 Lance File Format 基础上的数据集,利用 Lance 文件存储的灵活性,将类型、编码、版本、索引、删除等信息外置,来满足 AI Workloads 的灵活需求。
相比 Iceberg,它有什么优势呢?Iceberg 当前更多是面向分析查询场景,从以上功能角度来看,其实 Iceberg 也可以扩展支持到(支持 lance 数据文件、支持 lance 索引等),但是因为 Iceberg 已经相对成熟(事实上的数据湖表格式存储标准),新功能扩展比较谨慎,节奏上会比较保守。比较而言,Lance Table Format 就不会有这些历史包袱,对于当下 AI Workloads 爆发式需求,可以有针对性地灵活支持,如向量检索、文本检索、多模态数据存储查询等。
5. 参考资料
- Lance v2: A columnar container format for modern data
- Lance File 2.1: Smaller and Simpler
- Lance: Efficient Random Access in Columnar Storage through Adaptive Structural Encodings
转载请注明出处,本文永久链接:https://sharkdtu.github.io/posts/lance-format.html

