Flink 当前的计算任务调度是完全随机的,直接后果是各个 taskmanager 上运行的计算任务分布不均,进而导致 taskmanagers 之间的负载不均衡,用户在配置 taskmanager 资源时不得不预留较大的资源 buffer,带来不必要的浪费。为此,我们扩展了一种均衡调度策略,尽量保证每个 flink 算子的子任务均匀分布在所有的 taskmanagers 上,使得 taskmanagers 之间的负载相对均衡。
背景
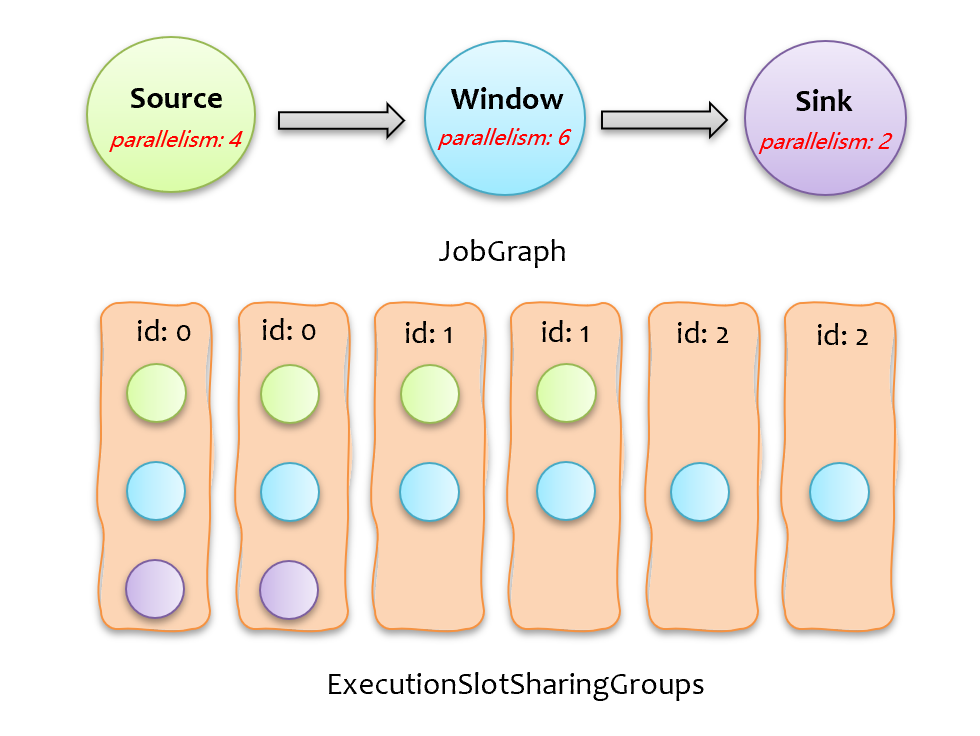
flink 在下发计算任务时,只要有空闲的 slot 资源就直接分配,并不考虑计算任务在 taskmanagers 上的分布情况,然而,不同算子的计算逻辑不同,如果一个算子是计算密集型的,其多个并行任务被扎堆调度下发到同一个 taskmanager 上,那么这个 taskmanager 的 cpu 负载压力会很大。更形象地,如下图所示的 JobGraph,有三个算子,最大并行度为 6,按照 flink 默认的 slot 共享调度机制,需要 6 个 slot。
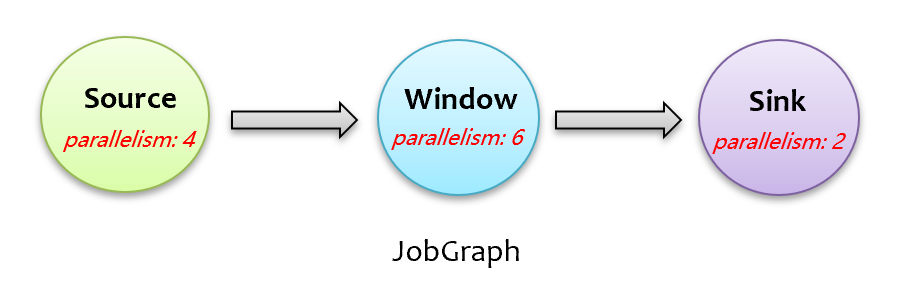
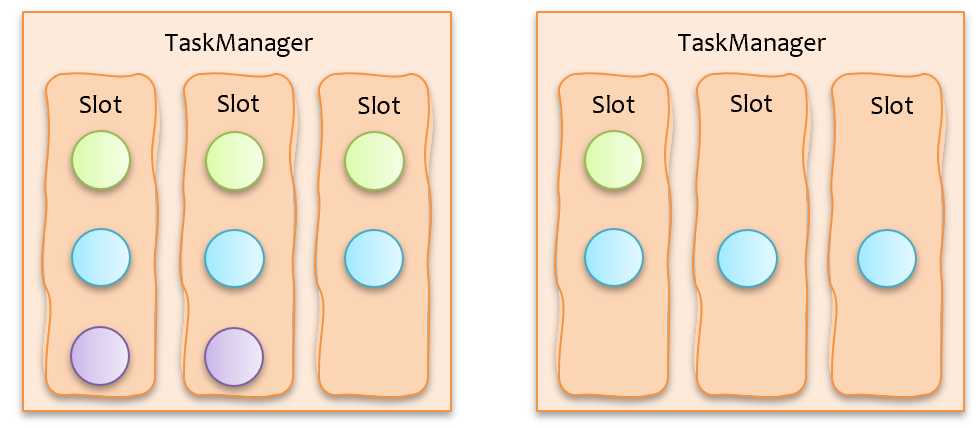
假如用户配置 2 个 taskmanager,每个 taskmanager 3 个 slot,按照目前 flink 的调度下发机制,很可能会出现如下图所示的计算任务分配情况,可以看到,source 和 sink 这两个算子的子任务被扎堆下发到同一个 taskmanager 上了,势必会造成该 taskmanager 上的负载(包括cpu、mem、network io 等)比其他 taskmanager 更高。
方案
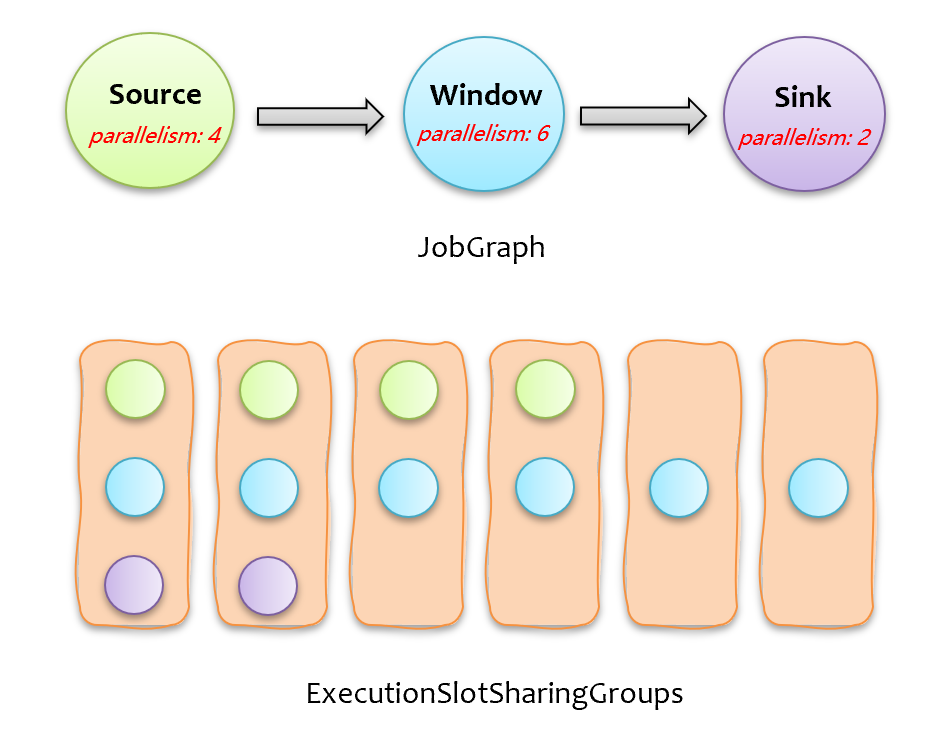
在阐述具体方案前,先通过一个例子简单介绍下当前 flink 计算任务分配下发的过程,如下图所示,上面的 JobGraph 在调度下发时,会创建一系列的 ExecutionSlotSharingGroup,每个 ExecutionSlotSharingGroup 包含不同算子的子任务,一个 ExecutionSlotSharingGroup 需要一个 slot,所以申请 slot 时,只需按照按 ExecutionSlotSharingGroup 数量来申请即可。
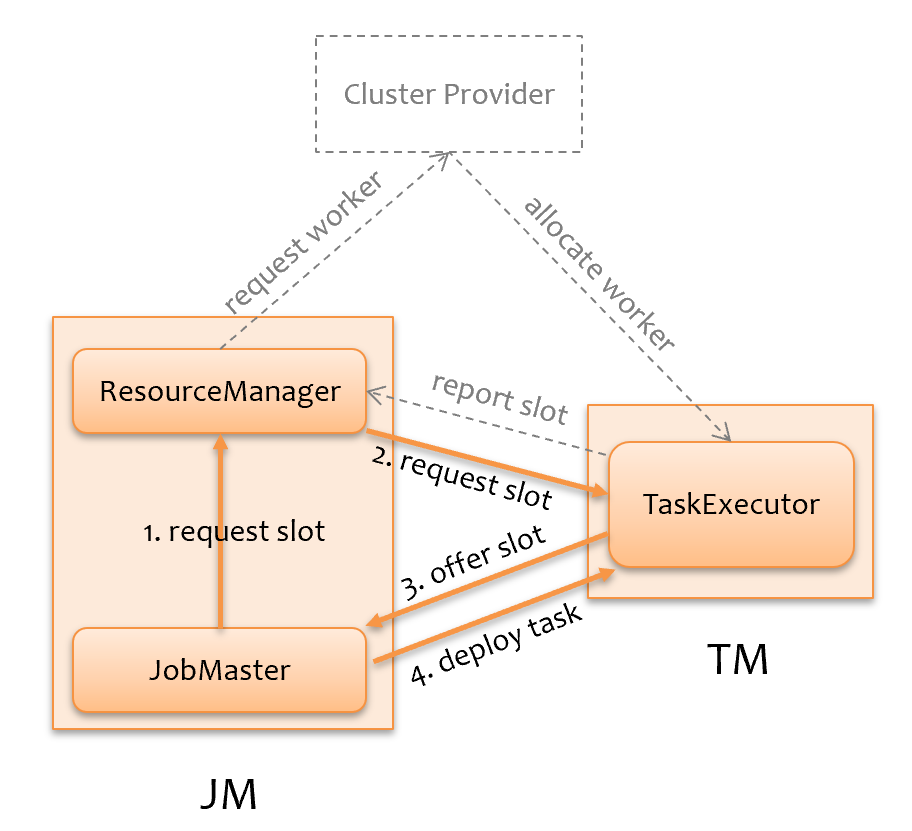
如下图所示,JobMaster 向 ResourceManager 声明请求 slot 个数,ResourceManager 判断是否有足够的 slot 资源,如果有,则将 job 信息发给 TaskExecutor 请求 slot,TaskExecutor 再向 JobMaster 提供 slot,JobMaster 即可下发计算任务;如果没有,则会尝试向集群申请资源,TaskExecutor 起来后会向 ResourceManager 上报 slot 资源信息。
计算任务分布不均衡本质原因是,JobMaster 申请到的 slot 不是一次性拿到的,每次 TaskExecutor 向 JobMaster 提供 slot 时,JobMaster 就将这部分 slot 分给 ExecutionSlotSharingGroup ,在分配的时候,并不考虑分布情况。
为了能有一个全局的分配视角,需要等所有 slot 到齐后,一把分配。问题就变成了:有 K 个大小不一的 ExecutionSlotSharingGroup,要放到 m*n = K 个 slot 里(m 为 tm 个数,n 为每个 tm 的 slot 数),尽量让每个 tm 上的 ExecutionSlotSharingGroup 分布均衡。为此,我们对每个 ExecutionSlotSharingGroup 分类编号,如果其包含的子任务所属的算子相同,会被分配同一个编号,如下图所示,总共有三类,相同计算负载的 ExecutionSlotSharingGroup 编号相同。
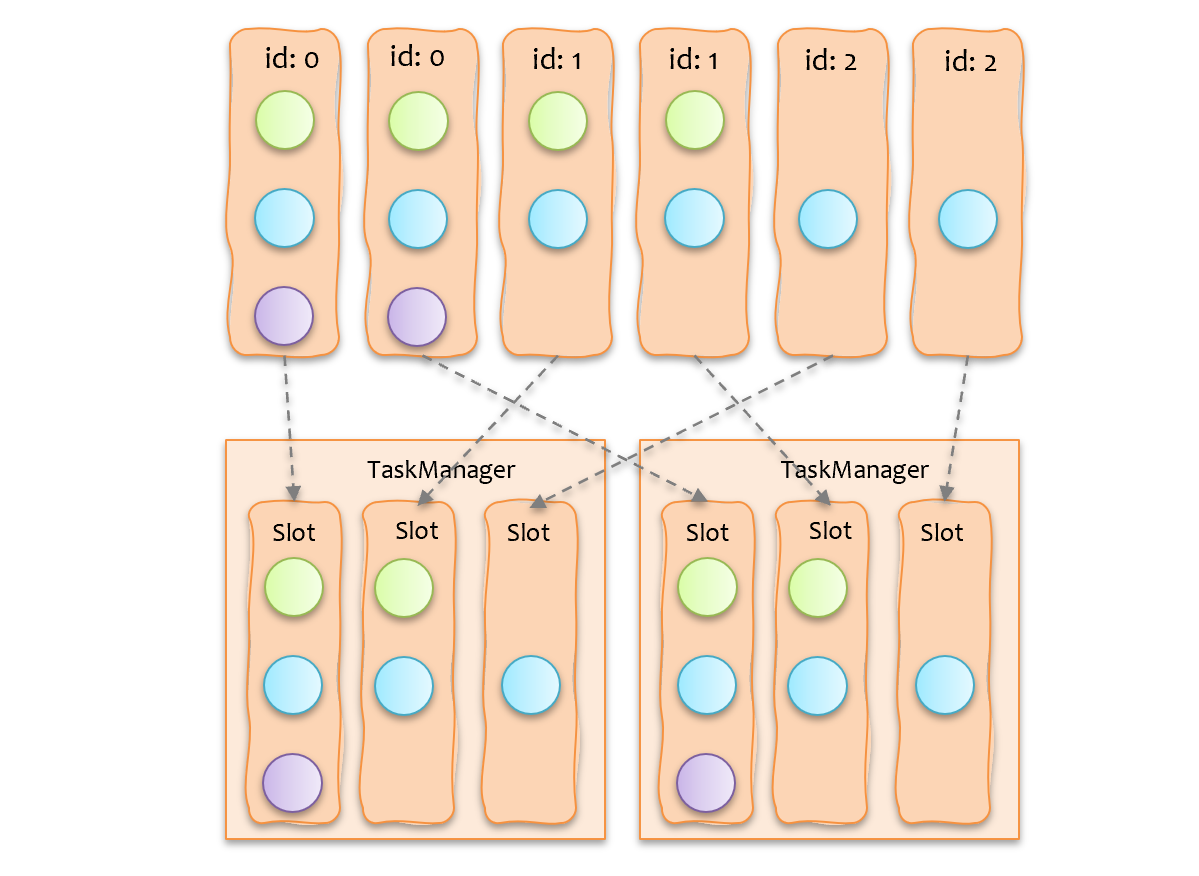
有了上述基础后,我们只需要实现一个算法,按 ExecutionSlotSharingGroup 类别 id,均匀分配到 taskmanager 中即可,如下图所示,可以看到,最终运行时,两个 taskmanager 上的负载是相对均衡的。
小结
本文介绍了 flink 均衡调度,目的是尽可能使计算任务在各 taskmanagers 上分布均衡,保证作业稳定性以及节省资源。该特性需要等所有 slot 全部到位一把分配,仅适用于流处理模式,对批处理意义不大。
转载请注明出处,本文永久链接:https://sharkdtu.github.io/posts/flink-schedule-balance.html

