通常来说,使用Spark-Streaming做无状态的流式计算是很方便的,每个batch时间间隔内仅需要计算当前时间间隔的数据即可,不需要关注之前的状态。但是很多时候,我们需要对一些数据做跨周期的统计,例如我们需要统计一个小时内每个用户的行为,我们定义的计算间隔(batch-duration)肯定会比一个小时小,一般是数十秒到几分钟左右,每个batch的计算都要更新最近一小时的用户行为,所以需要在整个计算过程中维护一个状态来保存近一个小时的用户行为。在Spark-1.6以前,可以通过updateStateByKey操作实现有状态的流式计算,从spark-1.6开始,新增了mapWithState操作,引入了一种新的流式状态管理机制。
背景
为了更形象的介绍Spark-Streaming中的状态管理,我们从一个简单的问题展开:我们需要实时统计近一小时内每个用户的行为(点击、购买等),为了简单,就把这个行为看成点击列表吧,来一条记录,则加到指定用户的点击列表中,并保证点击列表无重复。计算时间间隔为1分钟,即每1分钟更新近一小时用户行为,并将有状态变化的用户行为输出。
updateStateByKey
在Spark-1.6以前,可以通过updateStateByKey实现状态管理,其内部维护一个状态流来保存状态,上述问题可以通过如下实现完成:
1 | // 更新一个用户的状态 |
上述代码显示,我们只需要定义一个状态更新函数,传给updateStateByKey即可,Spark-Streaming会根据我们定义的更新函数,在每个计算时间间隔内更新内部维护的状态,最后把更新后的状态返回给我们。那么其内部是怎么做到的呢,简单来说就是cache+checkpoint+cogroup,状态更新流程如下图所示。
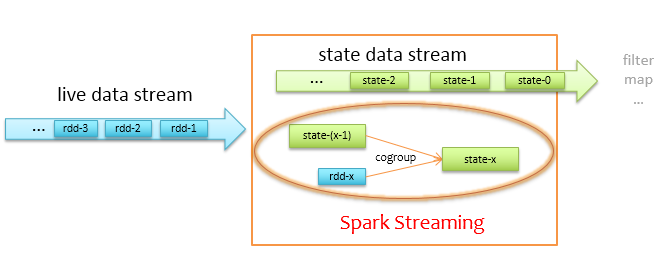
上图左边蓝色箭头为实时过来的数据流liveDStream,通过liveDStream.updateStateByKey的调用,会得到一个StateDStream,为方框中上面浅绿色的箭头,实际更新状态时,Spark-Streaming会将当前时间间隔内的数据rdd-x,与上一个时间间隔的状态state-(x-1)做cogroup操作,cogroup中做的更新操作就是我们前面定义的updateState函数。程序开始时,state-0状态为空,即由rdd-1去初始化state-1。另外,出于容错考虑,状态数据流StateDStream一般会做cache和定期checkpoint,程序因为机器宕机等原因挂掉可以从checkpoint处恢复状态。
但是,我们之前的问题描述是“输出有状态变化的用户行为”,通过updateStateByKey得到的是整个状态数据,这并不是我们想要的。同时在每次状态更新时,都需要将实时过来的数据跟全量的状态做cogroup计算,也就是说,每次计算都要将全量状态扫一遍进行比对,当计算随着时间的进行,状态数据逐步覆盖到全量用户,数据量慢慢增大,在做cogroup时遍历就变的越来越慢,使得在一个batch的时间内完成不了计算,导致后续数据堆积,最终挂掉。所以说,updateStateByKey并不能解决我们之前描述的那个问题。
mapWithState
从Spark-1.6开始,Spark-Streaming引入一种新的状态管理机制mapWithState,支持输出全量的状态和更新的状态,还支持对状态超时管理,用户可以自行选择需要的输出,通过mapWithState操作可以很方便地实现前面提出的问题。
1 | // 状态更新函数,output是输出,state是状态 |
上述代码显示,我们需要定义一个状态更新函数mappingFunc,该函数会更新指定用户的状态,同时会返回更新后的状态,将该函数传给mapWithState,并设置状态超时时间,Spark-Streaming通过根据我们定义的更新函数,在每个计算时间间隔内更新内部维护的状态,同时返回经过mappingFunc后的结果数据流,其内部执行流程如下图所示。
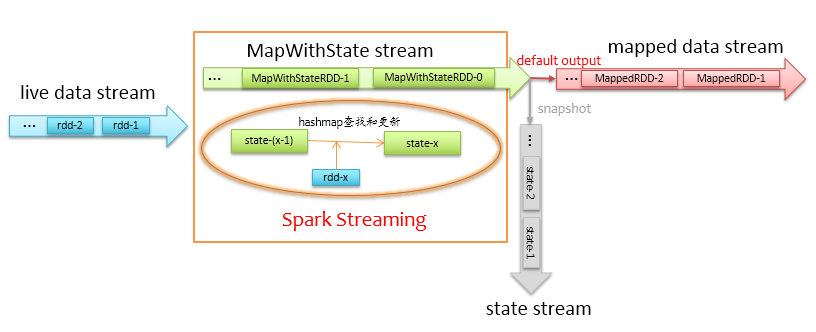
上图左边蓝色箭头为实时过来的数据流liveDStream,通过liveDStream.mapWithState的调用,会得到一个MapWithStateDStream,为方框中上面浅绿色的箭头,计算过程中,Spark-Streaming会遍历当前时间间隔内的数据rdd-x,在上一个时间间隔的状态state-(x-1)中查找指定的记录,并更新状态,更新操作就是我们前面定义的mappingFunc函数。这里的状态更新不再需要全量扫描状态数据了,状态数据是存在hashmap中,可以根据过来的数据快速定位到,详细的状态更新流程如下图所示。
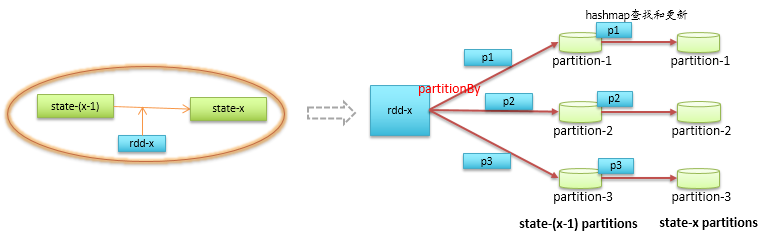
首先通过partitionBy将新来的数据分区到对应的状态分区上,每个状态分区中的仅有一条记录,类型为MapWithStateRDDRecord,它打包了两份数据,如下代码所示。
1 | case class MapWithStateRDDRecord[K, S, E]( |
其中stateMap保存当前分区内所有的状态,底层为hashmap类型,mappedData保存经过mappingFunc处理后的结果。这样,liveDStream经过mapWithState后就可以得到两份数据,默认输出的是mappedData这份,如果需要输出全量状态,则可以在mapWithState后调用snapshot函数获取。
| 输入 | mapWithState后的结果 | 调用stateSnapshots后的结果 |
|---|---|---|
| (200100101, 1) | (200100101, Set(1)) | (200100101, Set(1, 2)) |
| (200100101, 2) | (200100101, Set(1, 2)) | (200100102, Set(1)) |
| (200100102, 1) | (200100102, Set(1)) | |
| (200100101, 2) | (200100101, Set(1, 2)) |
上述实现看似很美好,基本可以满足大部分的流式计算状态管理需求。但是,经过实际测试发现,状态缓存太耗内存了,出于容错考虑,状态数据会做cache和定期checkpoint,默认情况下是10个batch的时间做一次checkpoint,cache的记忆时间是20个batch时间,也就是说最多会缓存20份历史状态,我们的用户数是10亿,不可能hold住这么大的量。最最奇葩的是,checkpoint时间间隔和cache记忆时间都是代码里写死的,而且缓存方式采用MEMORY_ONLY也是写死的(估计是出于hashmap查找性能的考虑)。
既然写死了,那我们就修改源代码,将cache的记忆时间改为一个batch的时间,即每次仅缓存最新的那份,但是实际运行时,状态缓存数据量还是很大,膨胀了10倍以上,原因是Spark-Streaming在存储状态时,除了存储我们必要的数据外,还会带一些额外数据,例如时间戳、是否被删除标记、是否更新标记等,再加上JVM本身内存布局的膨胀,最终导致10倍以上的膨胀,而且在状态没有完全更新完毕时,旧的状态不会删除,所以中间会有两份的临时状态,如下图所示。

所以说,在状态数据量较大的情况下,mapWithState还是处理不了,看其源码的注释也是@Experimental状态,这大概也解释了为什么有些可调参数写死在代码里:),对于状态数据量较小的情况,还是可以一试。
综上分析,我们之前提出的那个问题当前Spark-Streaming是没法儿解决了,那就这样放弃了么?既然Spark-Streaming的状态管理做的那么差,那我们不用它的状态管理就是了,看看是否可以通过其他方式来存状态。我们最后想到了Redis,它是全内存的KV存储,具有较高的访问性能,同时它还支持超时管理,可以通过借助Redis来缓存状态,实现mapWithState类似的工作。
使用Redis管理状态
通过前面的分析,我们不使用Spark自身的缓存机制来存储状态,而是使用Redis来存储状态。来一批新数据,先去redis上读取它们的上一个状态,然后更新写回Redis,逻辑非常简单,如下图所示。
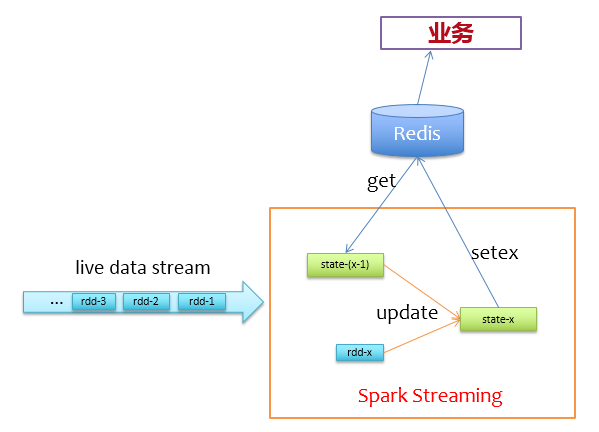
在实际实现过程中,为了避免对同一个key有多次get/set请求,所以在更新状态前,使用groupByKey对相同key的记录做个归并,对于前面描述的问题,我们可以先这样做:
1 | val liveDStream = ... // (userId, clickId) |
为了减少访问Redis的次数,我们使用pipeline的方式批量访问,即在一个分区内,一个一个批次的get/set,以提高Redis的访问性能,那么我们的更新逻辑就可以做到mapPartitions里面,如下代码所示。
1 | val updateAndflush = ( |
上述代码没有加容错等操作,仅描述实现逻辑,可以看到,函数mappingFunc会对每个分区的数据处理,实际计算时,会累计到batchSize才去访问Redis并更新,以降低访问Redis的频率。这样就不再需要cache和checkpoint了,程序挂了,快速拉起来即可,不需要从checkpoint处恢复状态,同时可以节省相当大的计算资源。
测试及优化选项
经过上述改造后,实际测试中,我们的batch时间为一分钟,每个batch约200W条记录,使用资源列表如下:
- driver-memory: 4g
- num-executors: 10
- executor-memory: 4g
- executor-cores: 3
每个executor上启一个receiver,则总共启用10个receiver收数据,一个receiver占用一个core,则总共剩下10*2=20个core可供计算用,通过调整如下参数,可控制每个batch的分区数为 10*(60*1000)/10000=60(10个receiver,每个receiver上(60*1000)/10000个分区)。1
spark.streaming.blockInterval=10000
为了避免在某个瞬间数据量暴增导致程序处理不过来,我们可以对receiver进行反压限速,只需调整如下两个参数即可,其中第一个参数是开启反压机制,即使数据源的数据出现瞬间暴增,每个receiver在收数据时都不会超过第二个参数的配置值,第二个参数控制单个receiver每秒接收数据的最大条数,通过下面的配置,一分钟内最多收 10*60*5000=300W(10个receiver,每个receiver一分钟最多收60*5000)条。
1 | spark.streaming.backpressure.enabled=true |
如果程序因为机器故障挂掉,我们应该迅速把拉重新拉起来,为了保险起见,我们应该加上如下参数让Driver失败重试4次,并在相应的任务调度平台上配置失败重试。
1 | spark.yarn.maxAppAttempts=4 |
此外,为了防止少数任务太慢影响整个计算的速度,可以开启推测,并增加任务的失败容忍次数,这样在少数几个任务非常慢的情况下,会在其他机器上尝试拉起新任务做同样的事,哪个先做完,就干掉另外那个。但是开启推测有个条件,每个任务必须是幂等的,否则就会存在单条数据被计算多次。
1 | spark.speculation=true |
经过上述配置优化后,基本可以保证程序7*24小时稳定运行,实际测试显示每个batch的计算时间可以稳定在30秒以内,没有上升趋势。
转载请注明出处,本文永久链接:https://sharkdtu.github.io/posts/spark-streaming-state.html

