最近在做BigData-Benchmark中PageRank测试,在测试时,发现有很多有趣的调优点,想到这些调优点可能是普遍有效的,现把它整理出来一一分析,以供大家参考。BigData-Benchmark中的Spark PageRank采用的是Spark开源代码examples包里的PageRank的代码,原理及代码实现都比较简单,下面我简单地介绍下。
PageRank基本原理介绍
PageRank的作用是评价网页的重要性,除了应用于搜索结果的排序之外,在其他领域也有广泛的应用,例如图算法中的节点重要度等。假设一个由4个页面组成的网络如下图所示,B链接到A、C,C连接到A,D链接到所有页面。
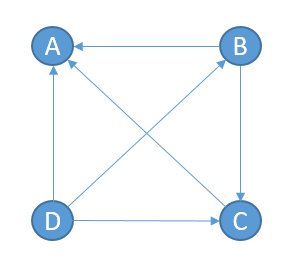
那么A的PR(PageRank)值分别来自B、C、D的贡献之和,由于B除了链接到A还链接到C,D除了链接到A还链接B、C,所以它们对A的贡献需要平摊,计算公式为:
$$ PR(A) = \frac {PR(B)} {2} + \frac {PR(C)} {1} + \frac {PR(D)} {3} \tag{1-1}$$
简单来说,就是根据链出总数平分一个页面的PR值:
$$ PR(A) = \frac {PR(B)} {L(B)} + \frac {PR(C)} {L(C)} + \frac {PR(D)} {L(D)} \tag{1-2}$$
对于上图中的A页面来说,它没有外链,这样计算迭代下去,PR值会全部收敛到A上去,所以实际上需要对这类没有外链的页面加上系数:
$$ PR(A) = d(\frac {PR(B)} {L(B)} + \frac {PR(C)} {L(C)} + \frac {PR(D)} {L(D)} + …) + \frac {1 - d} {N} \tag{1-3}$$
Spark PageRank Example
Spark Examples中给出了一个简易的实现,后续讨论的相关优化都是基于该简易实现,所以并不一定可以用来解决实际PageRank问题,这里仅用于引出关于Spark调优的思考。下面是原始版本的实现代码,我们称之为V1。
1 | /** |
上面的代码应该不难理解,它首先通过groupByKey得到每个url链接的urls列表,初始化每个url的初始rank为1.0,然后通过join将每个url的rank均摊到其链接的urls上,最后通过reduceByKey规约来自每个url贡献的rank,经过若干次迭代后得到最终的ranks,为了方便测试,上面代码29行我改成了一个空操作的action,用于触发计算。
优化一(Cache&Checkpoint)
从原始版本的代码来看,有些童鞋可能会觉得有必要对ranks做cache,避免每次迭代重计算,我们不妨先运行下原始代码,看看是否真的有必要,下图是指定迭代次数为3时的Job DAG图,其中蓝色的点表示被cache过。
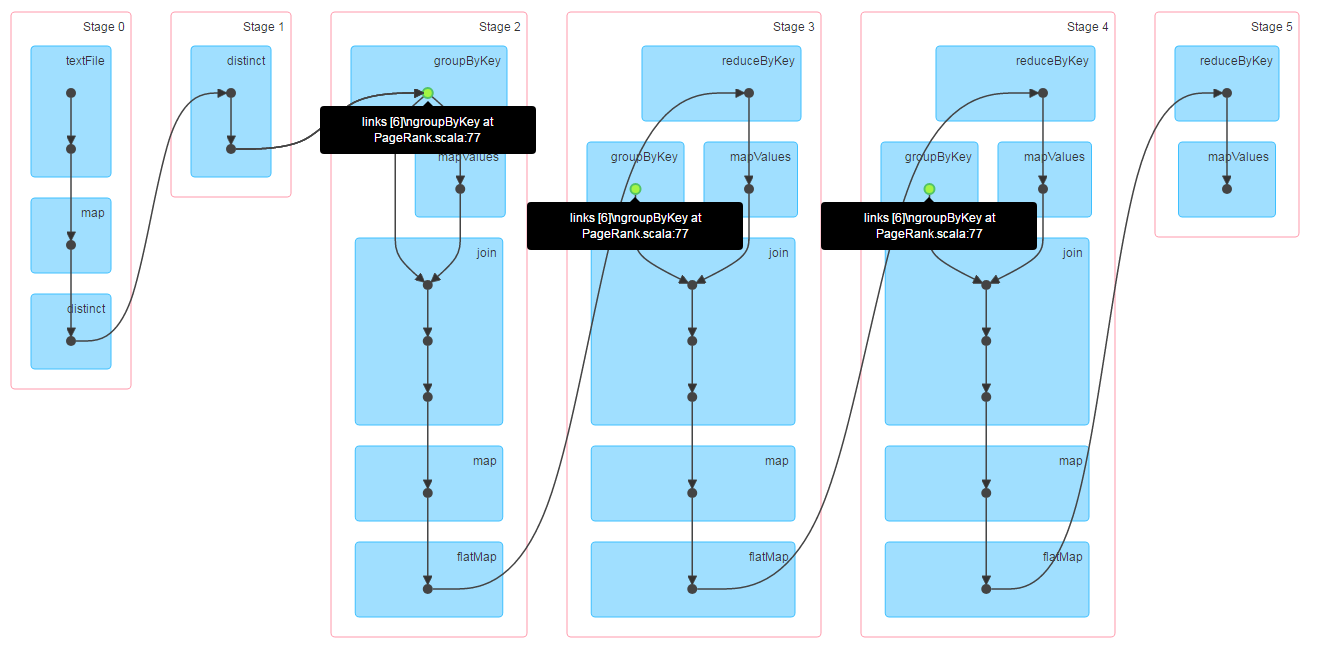
从上图可以看到,ranks没有被cache,3次迭代计算是在一个job里一气呵成的,所以没必要对ranks做cache,因为从整个代码来看,在迭代循环里没有出现action方法,所以迭代循环中不会触发job,仅仅是组织RDD之间的依赖关系。
但是,一般来说迭代次数都比较大,如果迭代1000甚至10000次,上述RDD依赖关系将变得非常长。一方面会增加driver的维护压力,很可能导致driver OOM;另一方面可能导致失败重算,单个task失败后,会根据RDD的依赖链从头开始计算。所以从容错以及可用性来说,上述代码实现是不可取的。所幸,Spark提供了checkpoint机制,来实现断链及中间结果持久化。
使用checkpoint,我们来改造上述迭代循环,在每迭代若干次后做一次checkpoint,保存中间结果状态,并切断RDD依赖关系链,迭代循环代码改造如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30...
var lastCheckpointRanks: RDD[(String, Double)] = null
for (i <- 1 to iters) {
val contribs = links.join(ranks).values.flatMap {
case (urls, rank) =>
val size = urls.size
urls.map(url => (url, rank / size))
}
ranks = contribs.reduceByKey(_ + _).mapValues(0.15 + 0.85 * _)
if (i % 10 == 0 && i != iters) {
ranks.cache().setName(s"iter$i: ranks")
ranks.checkpoint()
// Force action, just for trigger calculation
ranks.foreach(_ => Unit)
if (lastCheckpointRanks != null) {
lastCheckpointRanks.getCheckpointFile.foreach { ckp =>
val p = new Path(ckp)
val fs = p.getFileSystem(sc.hadoopConfiguration)
fs.delete(p, true)
}
lastCheckpointRanks.unpersist(blocking = false)
}
lastCheckpointRanks = ranks
}
}
// Final force action, like ranks.saveAsTextFile(outputPath)
ranks.foreach(_ => Unit)
上述代码中每隔10次迭代,做一次checkpoint,并强制触发计算。一定要注意,在做checkpoint前,一定要对要checkpoint的RDD做cache,否则会重计算。这里简单描述下checkpoint的计算流程: 调用rdd.checkpoint()仅仅是标记该RDD需要做checkpoint,并不会触发计算,只有在遇到action方法后,才会触发计算,在job执行完毕后,会启动checkpoint计算,如果RDD依赖链中有RDD被标记为checkpoint,则会对这个RDD再次触发一个job执行checkpoint计算。所以在checkpoint前,对RDD做cache,可以避免checkpoint计算过程中重新根据RDD依赖链计算。在上述代码中变量lastCheckpointRanks记录上一次checkpoint的结果,在一次迭代完毕后,删除上一次checkpoint的结果,并更新变量lastCheckpointRanks。
为了方便测试,我每隔3次迭代做一次checkpoint,总共迭代5次,运行上述代码,整个计算过程中会有一次checkpoint,根据前面checkpoint的计算描述可知,在代码15行处会有两个job,一个是常规计算,一个是checkpoint计算,checkpoint计算是直接从缓存中拿数据写到hdfs,所以计算开销是很小的。加上最终的一个job,整个计算过程中总共有3个job,下面是测试过程中job的截图,注意图中对应的行号跟上面贴的代码没有对应关系哦。

第一个job执行3次迭代计算,并将结果缓存起来,下面是第一个job的DAG:
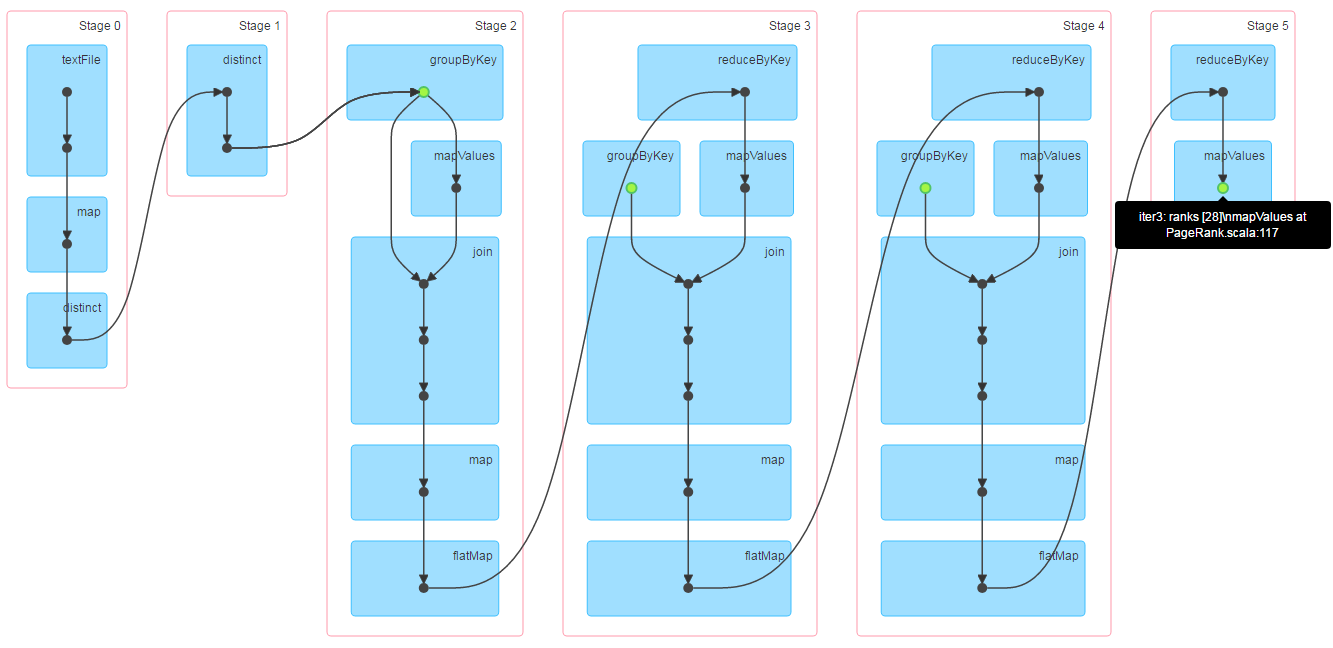
第二个job做checkpoint,由于需要checkpoint的RDD已经缓存了,所以不会重新计算,它会跳过依赖链中前面的RDD,直接从缓存中读取数据写到hdfs,所以前面的依赖链显示是灰色的:
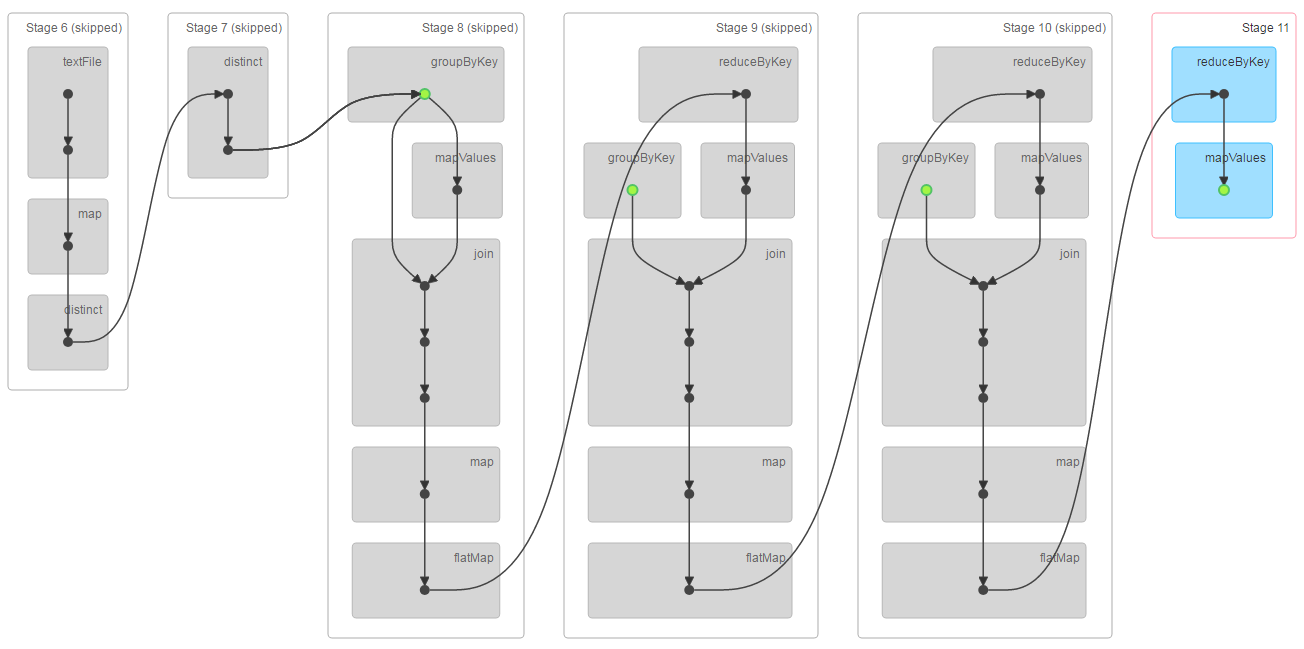
第三个job执行剩下的2次迭代计算,由于前3次迭代的结果已经做过checkpoint,所以这里的依赖链中不包含前3次迭代计算的依赖链,也就是说checkpoint起到了断链作用,这样driver维护的依赖链就不会越变越长了:
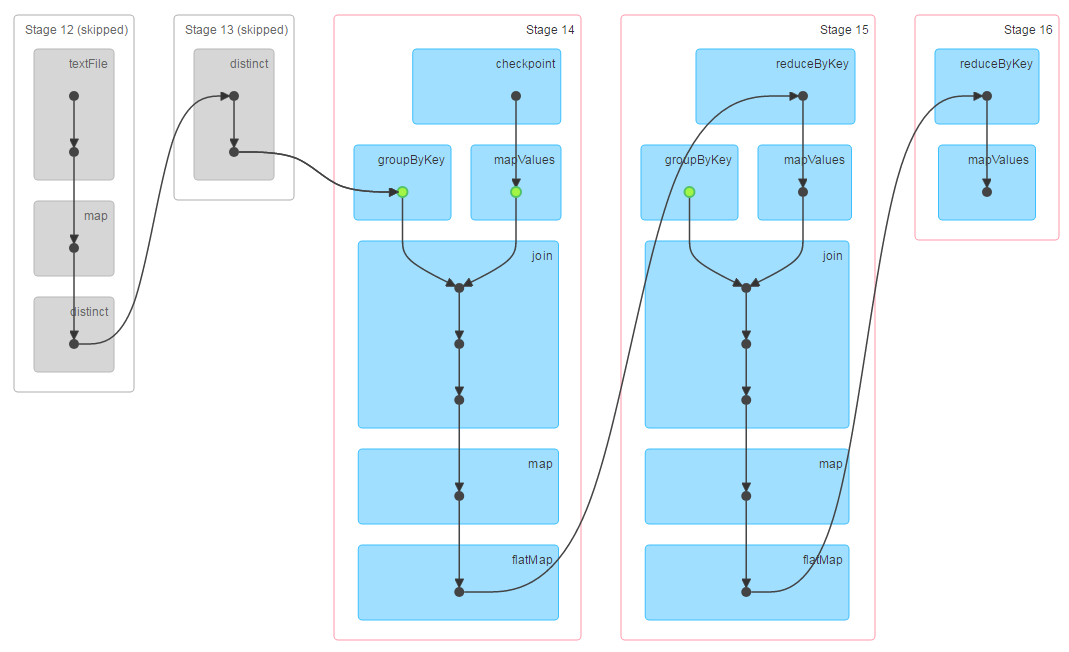
Tips: 对于迭代型任务,每迭代若干次后,做一次checkpoint
到这里,我们有一个稍微比较稳定的版本了,我们称之为V2。但是,一般实际场景中,links可能会特别大,建议使用MEMORY_ONLY_SER,并加上压缩参数spark.rdd.compress=true,这样可以大大降低内存的使用,同时性能不至于损失太多。在上面加了checkpoint的代码基础上,把所有使用cache的地方全部改成如下形式:1
2
3
4// Submit conf: spark.rdd.compress=true
links.persist(StorageLevel.MEMORY_ONLY_SER).setName("links")
...
ranks.persist(StorageLevel.MEMORY_ONLY_SER).setName(s"iter$i: ranks")
相同资源和参数下分别使用默认的MEMORY_ONLY和带压缩的MEMORY_ONLY_SER测试3次迭代的性能,下图是使用默认的MEMORY_ONLY方式缓存时,links在内存中的大小,可以看到links缓存后占用了6.6G内存:

改用带压缩的MEMORY_ONLY_SER的缓存方式后,links缓存后只占用了861.8M内存,仅为之前6.6G的12%:

通过在日志中打印运行时间,得到使用MEMORY_ONLY时运行时间为333s,使用MEMORY_ONLY_SER时运行时间为391s,性能牺牲了17%左右,所以使用MEMORY_ONLY_SER是以牺牲CPU代价来换取内存的一种较为稳妥的方案。在实际使用过程中需要权衡性能以及内存资源情况。
Tips: 内存资源较为稀缺时,缓存方式使用带压缩的
MEMORY_ONLY_SER代替默认的MEMORY_ONLY
优化二(数据结构)
在上述PageRank代码实现中,links中的记录为url -> urls,url类型为String,通常情况下,String占用的内存比Int、 Long等原生类型要多,在PageRank算法中,url完全可以被编码成一个Long型,因为在整个计算过程中根本没有用到url中的内容,这样就可以一定程度上减少links缓存时的内存占用。由于在我的测试数据中,url本身是由数字来表示的,所以在优化一V2代码的基础上再将links的定义改为如下代码,我们将该版本称之为V3:1
2
3
4
5
6
7
8...
val lines = sc.textFile(inputPath)
val links = lines.map { s =>
val parts = s.split("\\s+")
(parts(0).trim.toLong, parts(1).trim.toLong)
}.distinct().groupByKey()
links.persist(storageLevel).setName("links")
...
经过测试发现,url改成Long型后,使用MEMORY_ONLY缓存时,如下图所示,links仅占用2.5G,相比为String类型时的6.6G,缩小了一半多。此外,url改成Long型后,运行3次迭代的时间为278s,相比为String类型时的333s,性能提升了17%左右。

使用带压缩的MEMORY_ONLY_SER缓存时,如下图所示,links仅占用549.5M,相比为String类型时的861.8M,也缩小了近一半。此外,url改成Long型后,运行3次迭代的时间为306s,相比为String类型时的391s,性能提升了21%左右。

Tips: 实际开发中,尽可能使用原生类型,尤其是Numeric的原生类型(
Int,Long等)
优化三(数据倾斜)
经过前面两个优化后,基本可以应用到线上跑了,但是,可能还不够,如果我们的数据集中有少数url链接的urls特别多,那么在使用groupByKey初始化links时,少数记录的value(urls)可能会有溢出风险,由于groupByKey底层是用一个Array保存value,如果一个节点链接了数十万个节点,那么要开一个超大的数组,即使不溢出,很可能因为没有足够大的连续内存,导致频繁GC,进而引发OOM等致命性错误,通常我们把这类问题称之为数据倾斜问题。此外,在后续迭代循环中links和ranks的join也可能因为数据倾斜导致部分task非常慢甚至引发OOM,下图是groupByKey和join的示意图,左边是groupByKey后得到每个url链接的urls,底层用数组保存,在join时,shuffle阶段会将来自两个RDD相同key的记录通过网络拉到一个partition中,右边显示对url1的shuffle read,如果url1对应的urls特别多,join过程将会非常慢。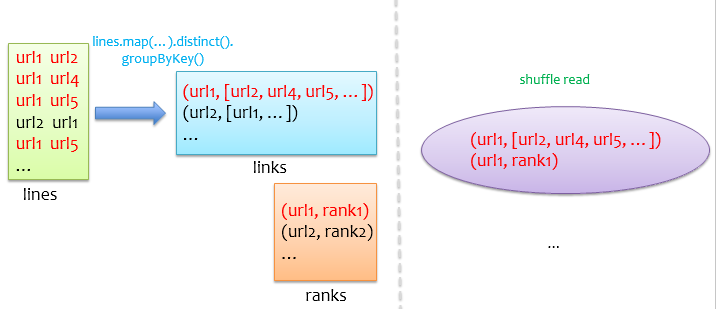
对key进行分桶
首先我们应该考虑避免使用groupByKey,这是导致后续数据倾斜的源头。既然可能存在单个key对应的value(urls)特别多,那么可以将key做一个随机化处理,例如将具有相同key的记录随机分配到10个桶中,这样就相当于把数据倾斜的记录给打散了,其大概原理如下图所示。
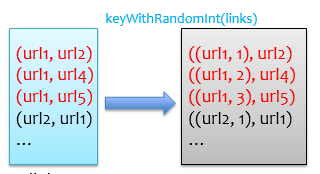
基于上面的理论基础,我们先得到不用groupByKey的links:1
2
3
4
5
6val lines = sc.textFile(inputPath)
val links = lines.map { s =>
val parts = s.split("\\s+")
(parts(0).trim.toLong, parts(1).trim.toLong)
}.distinct()
links.persist(storageLevel).setName("links")
再分析前面代码里的迭代循环,发现我们之前使用groupByKey很大一部分原因是想要得到每个key对应的urls size,我们可以单独通过reduceByKey来得到,reduceByKey会做本地combine,这个操作shuffle开销很小的:1
2
3// Count of each url's outs
val outCnts = links.mapValues(_ => 1).reduceByKey(_ + _)
outCnts.persist(storageLevel).setName("out-counts")
现在我们就可以使用cogroup将links、outCnts以及ranks三者join起来了,很快我们会想到使用如下代码:1
2
3
4val contribs = links.cogroup(outCnts, ranks).values.flatMap { pair =>
for (u <- pair._1.iterator; v <- pair._2.iterator; w <- pair._3.iterator)
yield (u, w/v)
}
但是!但是!但是!这样做还是会跟之前一样出现数据倾斜,因为cogroup执行过程中,在shuffle阶段还是会把links中相同key的记录分到同一个partition,也就说上面代码pair._1.iterator也可能非常大,这个iterator底层也是Array,面临的问题基本没解决。
所以我们就要考虑使用前面介绍的分桶方法了,对links中的每条记录都随机打散到10个桶中,那么相同key的记录就会被随机分到不同桶中了:1
2
3def keyWithRandomInt[K, V](rdd: RDD[(K, V)]): RDD[((K, Int), V)] = {
rdd.map(x => ((x._1, Random.nextInt(10)), x._2))
}
然而,cogroup是按照key进行join的,就是说它把来自多个RDD具有相同key的记录汇聚到一起计算,既然links的key已经被我们改变了,那么outCnts和ranks也要变成跟links相同的形式,才能join到一起去计算:1
2
3
4
5
6
7def expandKeyWithRandomInt[K, V](rdd: RDD[(K, V)])
: RDD[((K, Int), V)] = {
rdd.flatMap { x =>
for (i <- 0 until 10)
yield ((x._1, i), x._2)
}
}
有了这个基础后,我们就可以将前面的cogroup逻辑修改一下,让他们能够顺利join到一块儿去:1
2
3
4
5
6
7val contribs = keyWithRandomInt(links).cogroup(
expandKeyWithRandomInt(outCnts),
expandKeyWithRandomInt(ranks)
).values.flatMap { pair =>
for (u <- pair._1.iterator; v <- pair._2.iterator; w <- pair._3.iterator)
yield (u, w/v)
}
我们将该版本称之为V4,将上述逻辑整理成如下图,可以看到,其实我们对outCnts和ranks做了膨胀处理,才能保证cogroupshuffle阶段对于links中的每条记录,都能找到与之对应的outCnts和ranks记录。
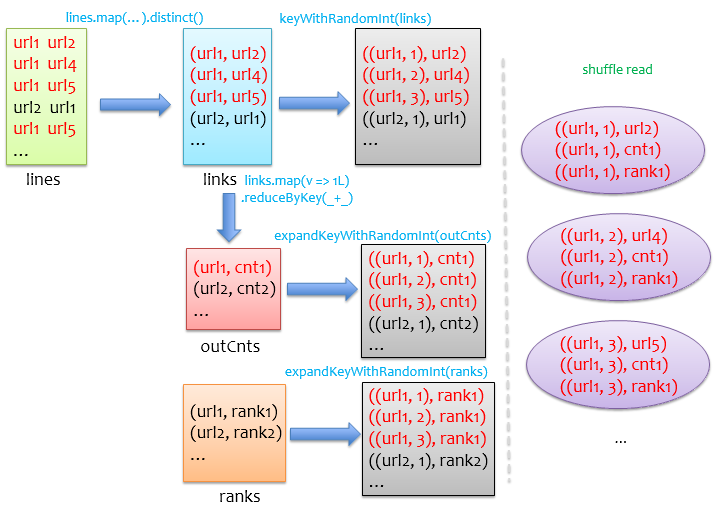
其实这种做法会极大地损失性能,虽然这样做可能把之前OOM的问题搞定,能够不出错的跑完,但是由于数据膨胀,实际跑起来是非常慢的,不建议采用这种方法处理数据倾斜问题。这里仅仅引出一些问题让我们更多地去思考。
拆分发生倾斜的key
有了前面的分析基础,我们知道对key分桶的方法,是不加区分地对所有key都一股脑地处理了,把不倾斜的key也当做倾斜来处理了,其实大部分实际情况下,只有少数key有倾斜,如果大部分key都倾斜那就不是数据倾斜了,那叫数据量特别大。所以我们可以考虑对倾斜的key和不倾斜的key分别用不同的处理逻辑,对不倾斜的key,还是用原来groupByKey和join方式来处理,对倾斜的key可以考虑使用broadcast来实现map join,因为倾斜的key一般来说是可数的,其对应的outCnts和ranks信息在我们PageRank场景里也不会很大,所以可以使用广播。
首先我们把链接的urls个数超过1000000的key定义为倾斜key,使用下面代码将links切分为两部分:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35val lines = sc.textFile(path)
val links = lines.map { s =>
val parts = s.split("\\s+")
(parts(0).trim.toLong, parts(1).trim.toLong)
}.distinct()
links.persist(storageLevel).setName("links")
// Count of each url's outs
val outCnts = links.mapValues(_ => 1L).reduceByKey(_ + _)
.persist(storageLevel).setName("out-counts")
// Init ranks
var ranks = outCnts.mapValues(_ => 1.0)
.persist(storageLevel).setName("init-ranks")
// Force action, just for trigger calculation
ranks.foreach(_ => Unit)
val skewedOutCnts = outCnts.filter(_._2 >= 1000000).collectAsMap()
val bcSkewedOutCnts = sc.broadcast(skewedOutCnts)
val skewed = links.filter { link =>
val cnts = bcSkewedOutCnts.value
cnts.contains(link._1)
}.persist(storageLevel).setName("skewed-links")
// Force action, just for trigger calculation
skewed.foreach(_ => Unit)
val noSkewed = links.filter { link =>
val cnts = bcSkewedOutCnts.value
!cnts.contains(link._1)
}.groupByKey().persist(storageLevel).setName("no-skewed-links")
// Force action, just for trigger calculation
noSkewed.foreach(_ => Unit)
links.unpersist(blocking = false)
首先统计出链接数超过1000000的key,广播到每个计算节点,然后过滤links,如果key在广播变量中则为倾斜的数据,否则为非倾斜的数据,过滤完毕后原始links被销毁。下面就可以在迭代循环中分别处理倾斜的数据skewed和非倾斜的数据noSkewed了。
对noSkewed使用原来的方法:1
2
3
4
5val noSkewedPart = noSkewed.join(ranks).values.flatMap {
case (urls, rank) =>
val size = urls.size
urls.map(url => (url, rank / size))
}
对skewed使用broadcast方式实现map join,类似地,要把倾斜的key对应的rank收集起来广播,之前的cogroup中的outCnts和ranks在这里就都被广播了,所以可以直接在map操作里完成对skewed中的数据处理:1
2
3
4
5
6
7
8
9
10val skewedRanks = ranks.filter { rank =>
val cnts = bcSkewedOutCnts.value
cnts.contains(rank._1)
}.collectAsMap()
val bcSkewedRanks = sc.broadcast(skewedRanks)
val skewedPart = skewed.map { link =>
val cnts = bcSkewedOutCnts.value
val ranks = bcSkewedRanks.value
(link._2, ranks(link._1)/cnts(link._1))
}
最后将两部分的处理结果union一下:1
val contribs = noSkewedPart.union(skewedPart)
后面的逻辑就跟前面一样了,我们将该版本称之为V5。分别测V3和V5版本代码,迭代3次,在没有数据倾斜的情况下,相同数据、资源和参数下V3运行时间306s,V5运行时间311s,但是在有数据倾斜的情况下,相同数据、资源和参数下V3运行时间722s并伴有严重的GC,V5运行时间472s。可以发现V5版本在不牺牲性能的情况可以解决数据倾斜问题,同时还能以V3相同的性能处理不倾斜的数据集,所以说V5版本更具通用性。
Tips: 对有倾斜的数据集,将倾斜的记录和非倾斜的记录切分,对倾斜的记录使用map join来解决由于数据倾斜导致少数task非常慢的问题
优化四(资源利用最大化)
通过前面几个优化操作后,V5版本基本可以用于线上例行化跑作业了,但是部署到线上集群,面临如何给资源的困扰。为了测试方便,测试数据集中没有数据倾斜,下面就拿V5来测试并监控资源利用情况。
原始测试数据(使用带压缩的MEMORY_ONLY_SER缓存方式)情况如下表:
| 磁盘中大小 | links缓存大小 |
分区数 |
|---|---|---|
| 1.5g | 549.5M | 20 |
运行3次迭代,一开始大概估计使用如下资源,使用5个executor,每个executor配2个core,一次并行运行10个partition,20个partition 2轮task就可以跑完:
| driver_mem | num_executor | executor_mem | executor_cores |
|---|---|---|---|
| 4g | 5 | 2g | 2 |
在提交参数中加上如下额外JVM参数,表示分别对driver和executor在运行期间开启Java Flight Recorder:1
2spark.driver.extraJavaOptions -XX:+UnlockCommercialFeatures -XX:+FlightRecorder -XX:StartFlightRecording=filename=<LOG_DIR>/driver.jfr,dumponexit=true
spark.executor.extraJavaOptions -XX:+UnlockCommercialFeatures -XX:+FlightRecorder -XX:StartFlightRecording=filename=<LOG_DIR>/excutor.jfr,dumponexit=true
运行完毕后,统计运行时间为439s,将driver.jfr和excutor.jfr拿到开发机上来,打开jmc分析工具(位于java安装目录bin/下面),首先我们看driver的监控信息,主页如下图所示,可以看到driver的cpu占用是很小的:
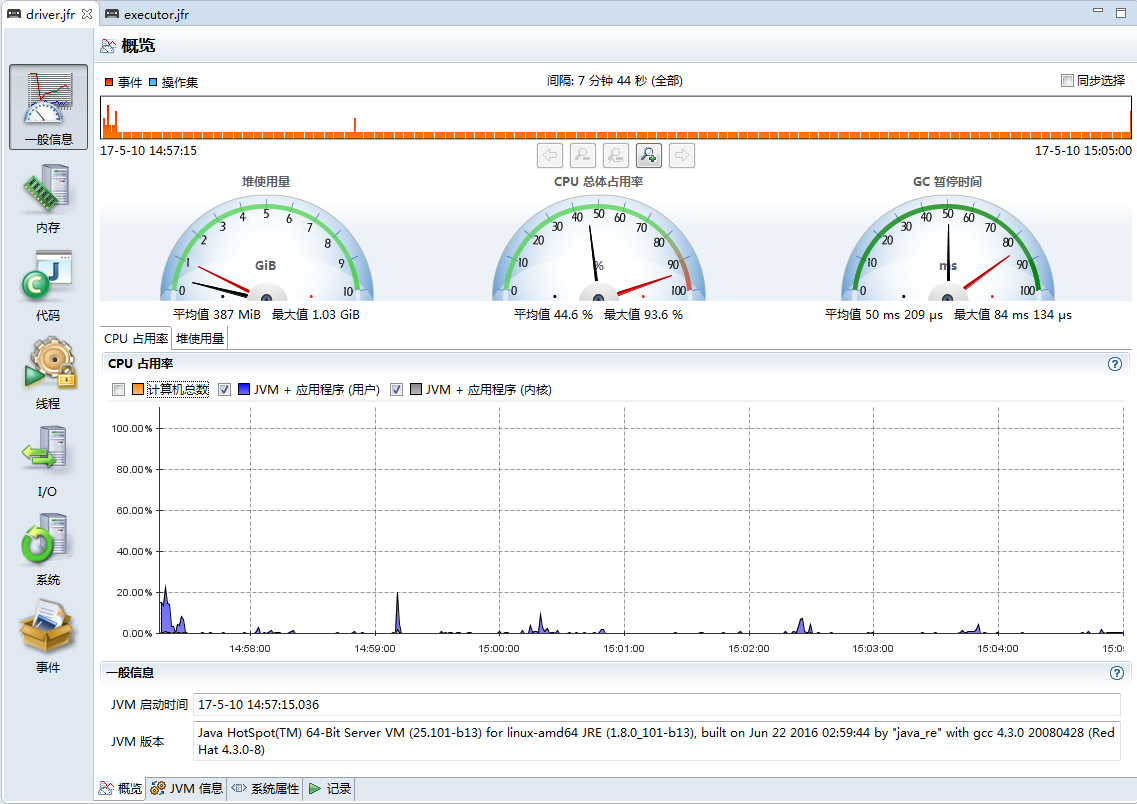
切到内存tab,把物理内存的两个勾选去掉,可以看到driver的内存使用曲线,我们给了4g,但是实际上最大也就用了差不多1g,看下图中的GC统计信息,没有什么瓶颈。
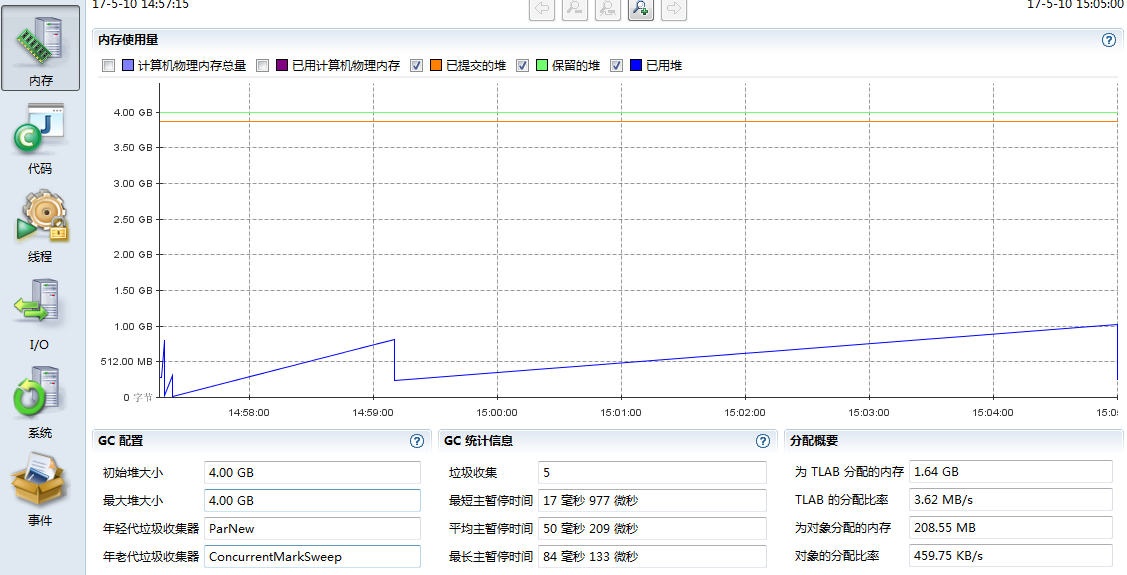
所以给driver分配4g是浪费的,我们把它调到2g,虽然实际上只用了大概1g,这里多给driver留点余地,其他配置不变,重新提交程序,统计运行时间为443s,跟4g时运行时间439s差不多。
再来看executor的监控信息,主页如下图所示,可以看到executor的cpu利用明显比driver多,因为要做序列化、压缩以及排序等。
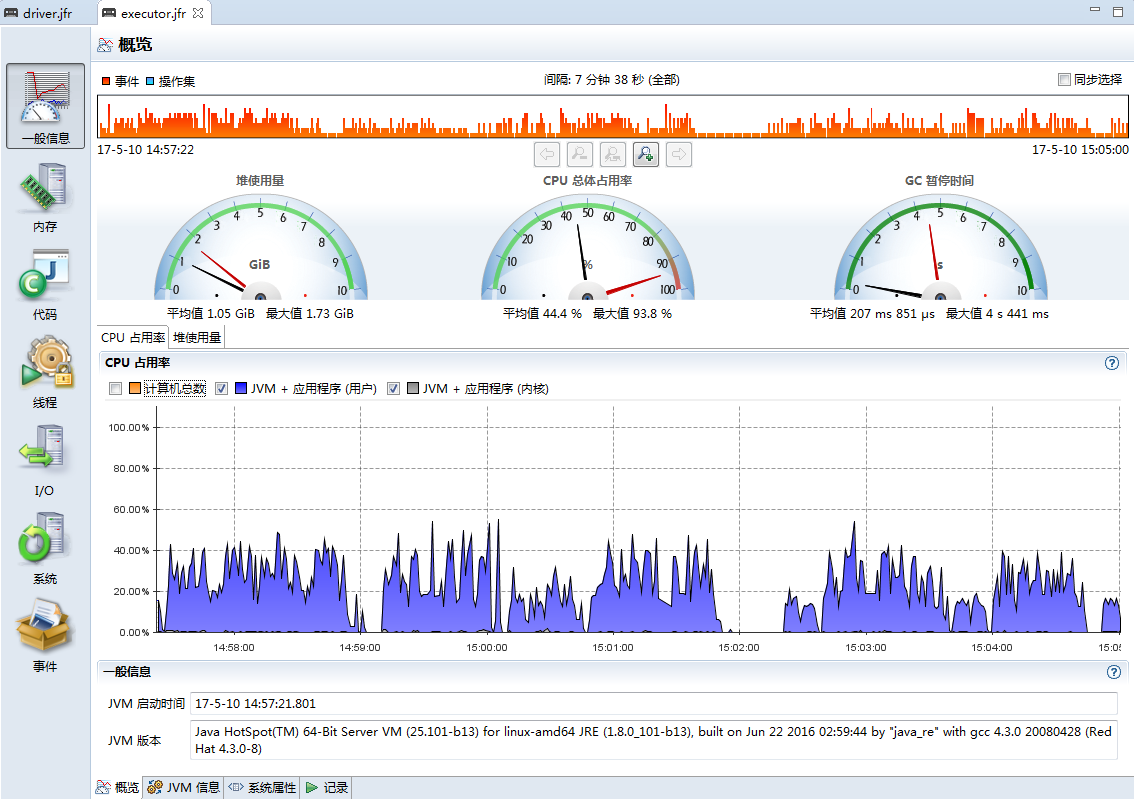
再切到内存tab,可以看到executor的内存使用波动较大,最大内存使用差不多1.75g,我们给了2g,还是相当合适的。但是看下面的GC统计信息,发现最长暂停4s多,而且垃圾回收次数也较多。
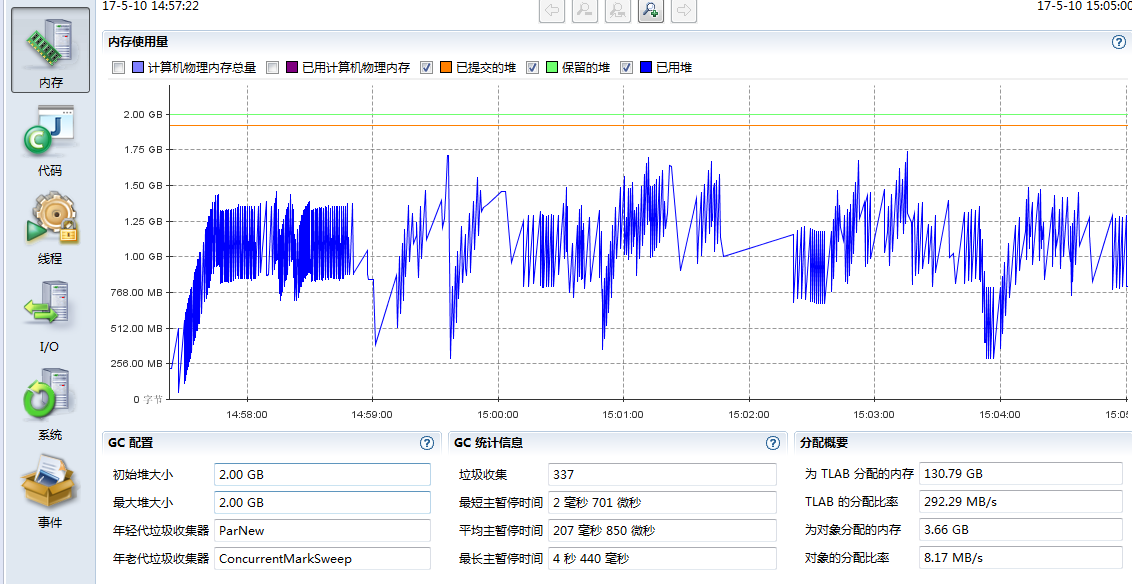
为此,我们切到”GC时间”tab,可以看到,GC还是比较频繁的,还有一次持续4s多的GC,看右边GC类型,对最长暂停时间从大到小排序,居然有几个SerialOld类型的GC,其他一部分是ParNew类型GC,一部分是CMS类型的GC,没有出现FULL GC,下面先分析内存使用,回过头来再分析这里出现的诡异SerialOld。
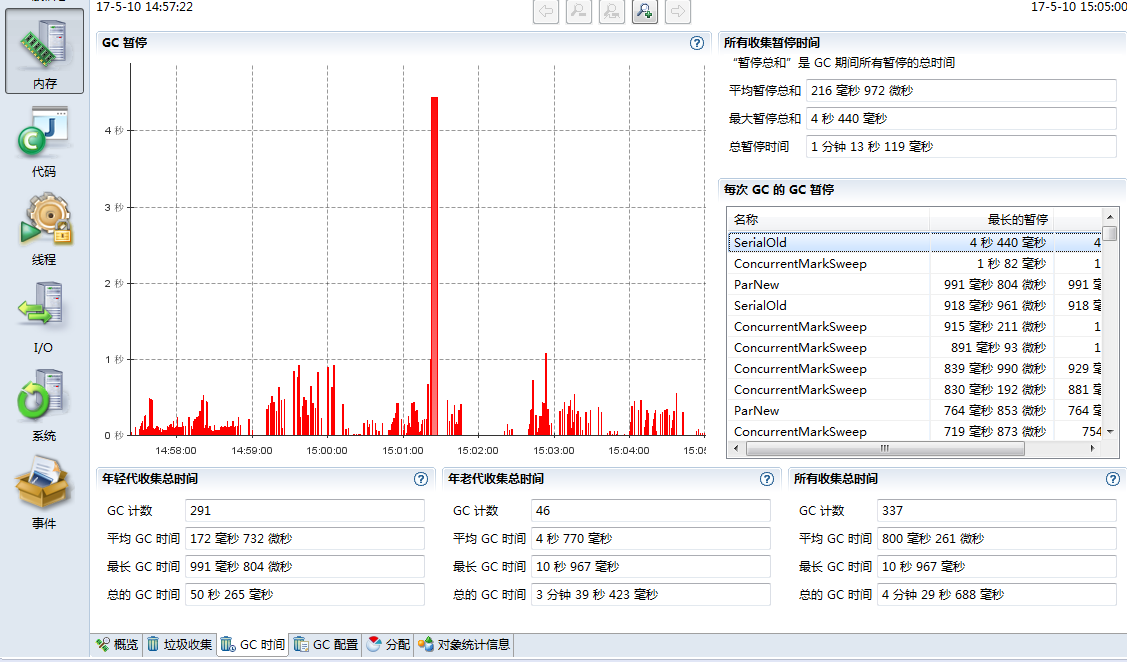
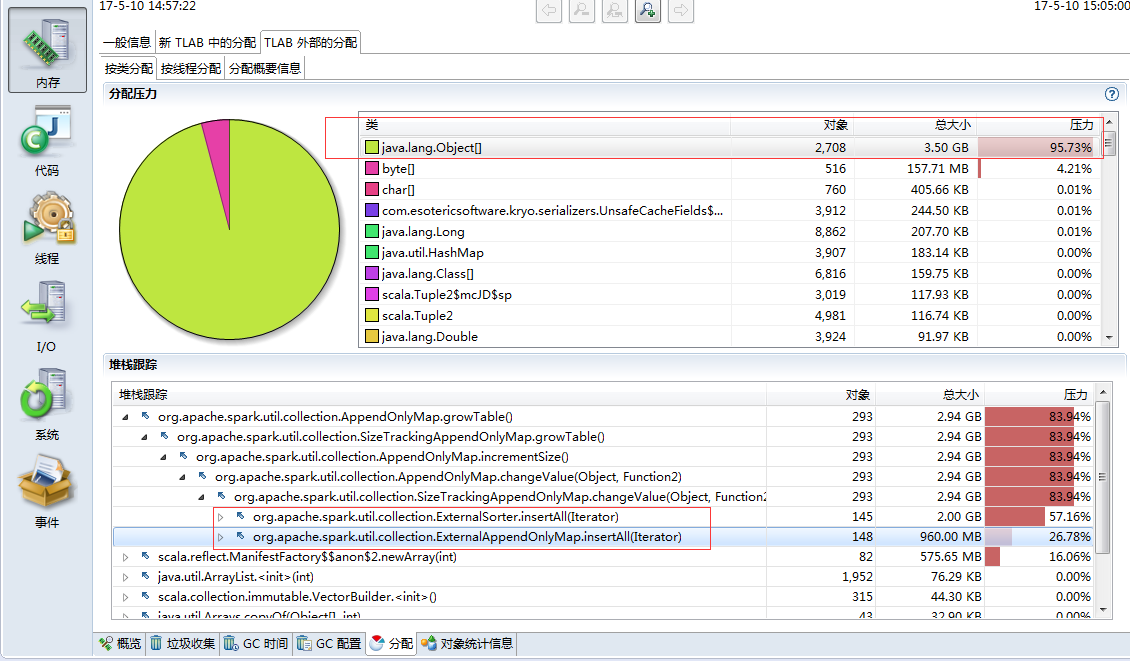
我们再看下堆内存大对象占用情况,大对象主要是在ExternalAppendOnlyMap和ExternalSorter中,ExternalAppendOnlyMap用于存放shuffle read的数据,ExternalSorter用于存放shuffle write前的数据,用于对记录排序,这两个数据结构底层使用Array存储数据,所以这里表现为大对象。
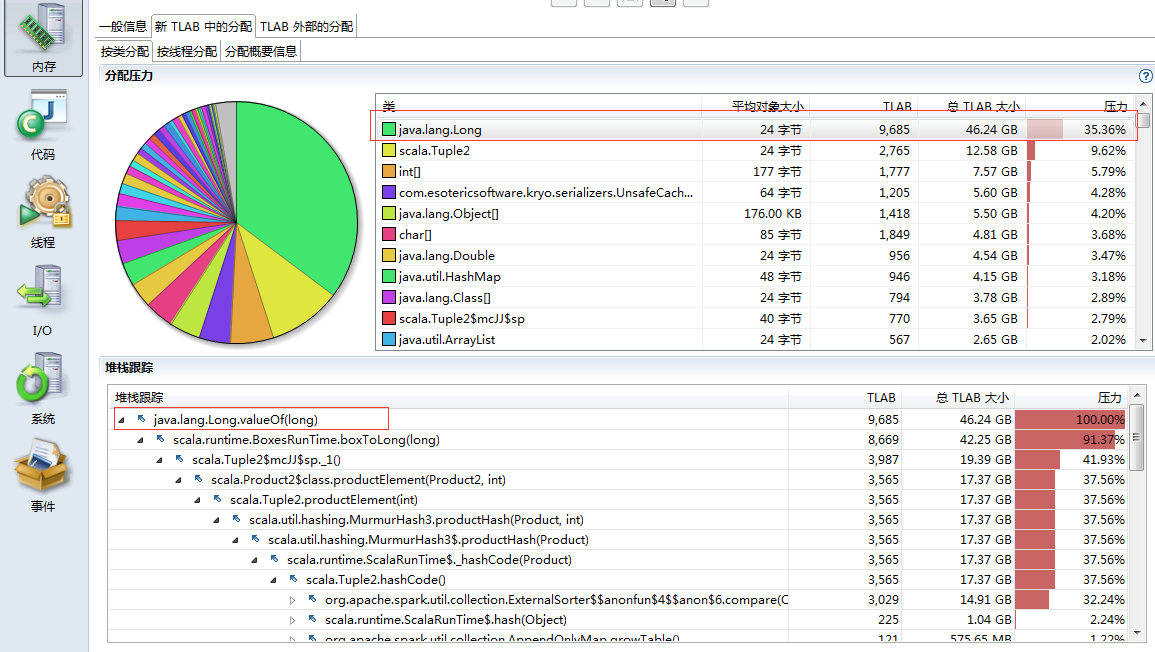
切换到TLAB,再细化到小对象,可以看到大部分是Long型(url),展开堆栈跟踪,大部分是用在shuffle阶段,因为在join时,一方面会读取groupByKey后的links,用于做shuffle write,一方面在shuffle read阶段,将相同key的links和ranks拉到一起做join计算。
所以总体来说,内存情况是符合业务逻辑的,没有出现莫名其妙的内存占用。让人有点摸不清头脑的是,GC信息中有SerialOld这玩意儿,我明明用了CMS垃圾回收方式,经过一番Google查阅资料,”Concurrent Mode Failure”可能导致Serial Old的出现,查阅”Concurrent Mode Failure”发生的原因: 当CMS GC正进行时,此时有新的对象要进入老年代,但是老年代空间不足。仔细分析,个人觉得可能是因为CMS GC后存在较多的内存碎片,而我们的程序在shuffle阶段底层使用Array,需要连续内存,导致CMS GC过程中出现了”Concurrent Mode Failure”,才退化到Serial Old,Serial Old是采用标记整理回收算法,回收过程中会整理内存碎片。这样看来,应该是CMS GC过程中,老年代空间不足导致的,从两个方面考虑优化下,一是增加老年代内存占比,二是减小参数-XX:CMSInitiatingOccupancyFraction,降低触发CMS GC的阈值,让CMS GC及早回收老年代。
首先我们增加老年代内存占比,也就是降低新生代内存占比,默认-XX:NewRatio=2,我们把它改成-XX:NewRatio=3,将老年代内存占比由2/3提升到3/4,重新提交程序,得到executor.jfr,打开GC监控信息,发现有很大的改善,不在出现Serial Old类型的GC了,最长暂停时间从原来的4s降低到600ms左右,整体运行时间从448s降低到436s。
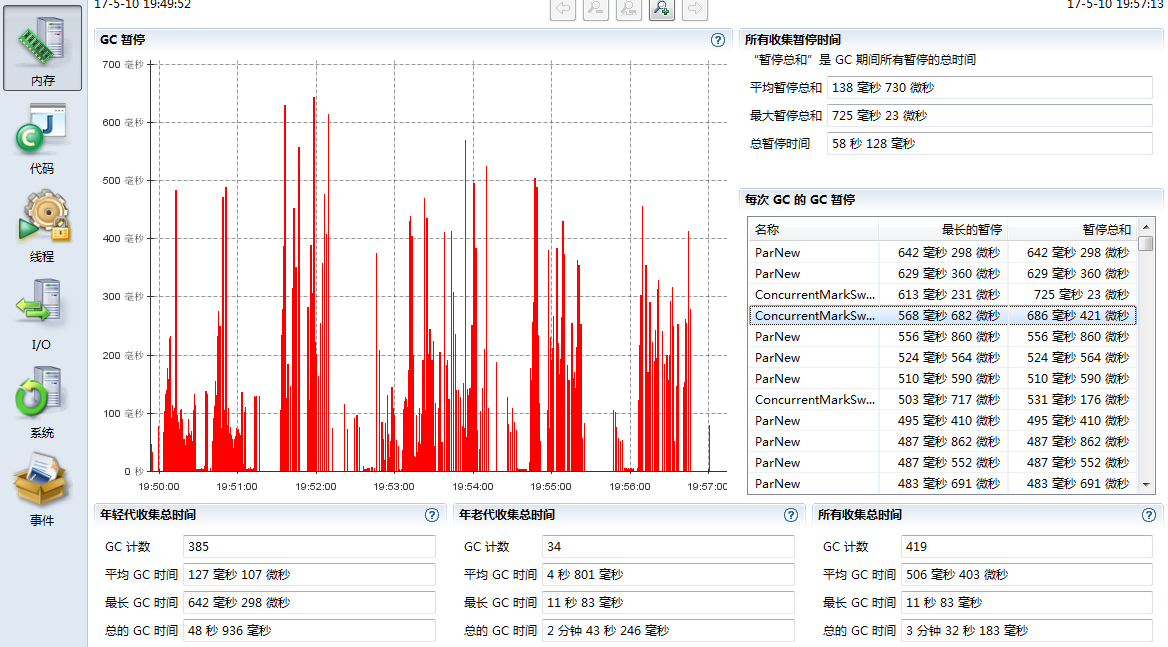
把上述-XX:NewRatio=3去掉,设置参数-XX:CMSInitiatingOccupancyFraction=60,重新提交程序,得到executor GC的监控信息,发现GC最大暂停时间也降下来了,但是由于老年代GC的频率加大了,整体运行时间为498s,比原来的436s还要长。
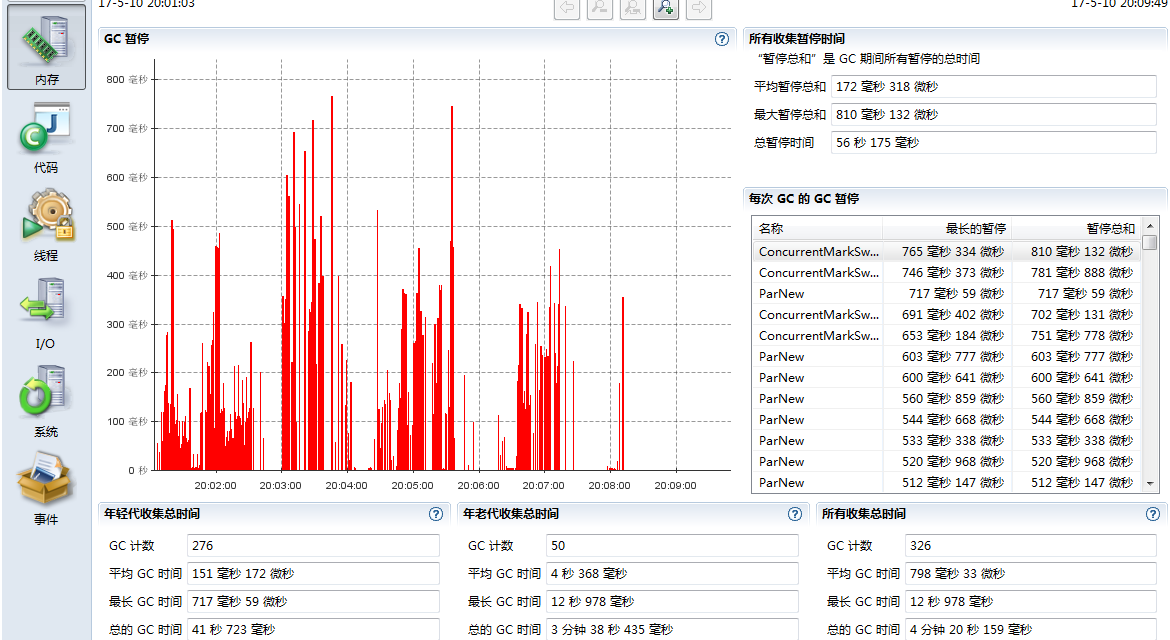
综合考虑以上信息,增加executor的jvm启动参数-XX:NewRatio=3,能把GC状态调整到一个较优的状态。
总结
Spark给我们提供了一种简单灵活的大数据编程框架,但是对于很多实际问题的处理,还应该多思考下如何让我们写出来的应用程序更高效更节约,以上几个调优点是可以推广到其他应用的,在我们编写spark应用程序时,通过这种思考也可以加速我们对spark的理解。
转载请注明出处,本文永久链接:https://sharkdtu.github.io/posts/spark-app-optimize.html

