TensorFlow从15年10月开源至今,可谓是发展迅猛,从v0.5到如今的v2.0.0-alpha,经历了无数个功能特性的升级,性能、可用性、易用性等都在稳步提升。相对来说,对于我们工业界,大家可能更关注分布式TensorFlow的发展,本文尝试梳理下分布式TensorFlow从问世到现在经历过的变迁。
分布式TensorFlow运行时基本组件
用户基于TensorFlow-API编写好代码提交运行,整体架构如下图所示。
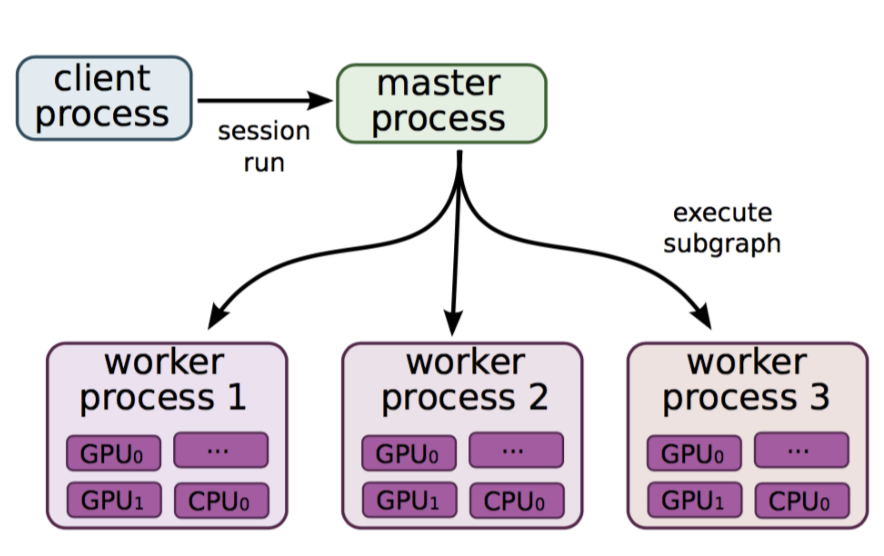
Client
可以把它看成是TensorFlow前端,它支持多语言的编程环境(Python/C++/Go/Java等),方便用户构造各种复杂的计算图。Client通过Session连接TensorFlow后端,并启动计算图的执行。Master
Master根据要计算的操作(Op),从计算图中反向遍历,找到其所依赖的最小子图,然后将该子图再次分裂为多个子图片段,以便在不同的进程和设备上运行这些子图片段,最后将这些子图片段派发给Worker执行。Worker
Worker按照计算子图中节点之间的依赖关系,根据当前的可用的硬件环境(GPU/CPU/TPU),调用Op的Kernel实现完成运算。
在分布式TensorFlow中,参与分布式系统的所有节点或者设备统称为一个Cluster,一个Cluster中包含很多Server,每个Server去执行一项Task,Server和Task是一一对应的。所以,Cluster可以看成是Server的集合,也可以看成是Task的集合,TensorFlow为各个Task又增加了一个抽象层,将一系列相似的Task集合称为一个Job。形式化地,一个TensorFlow Cluster可以通过以下json来描述:1
2
3
4
5
6
7
8
9
10
11{
"${job_name1}": [
"${host1}:${port1}",
"${host2}:${port2}",
"${host3}:${port3}"
],
"${job_name2}": [
"${host4}:${port4}",
"${host5}:${port5}"
]
}
job用job_name(字符串)标识,而task用index(整数索引)标识,那么cluster中的每个task可以用job的name加上task的index来唯一标识,例如‘/job:worker/task:1’。一组Task集合(即Job)有若干个Server(host和port标识),每个Server上会绑定两个Service,就是前面提到的Master Service和Worker Service,Client通过Session连接集群中的任意一个Server的Master Service提交计算图,Master Service负责划分子图并派发Task给Worker Service,Worker Service则负责运算派发过来的Task完成子图的运算。下面详细阐述分布式TensorFlow不同架构的编程模型演进。
基于PS的分布式TensorFlow编程模型
分布式TensorFlow设计之初是沿用DistBelief(Google第一代深度学习系统)中采用的经典ps-worker架构,如下图所示。
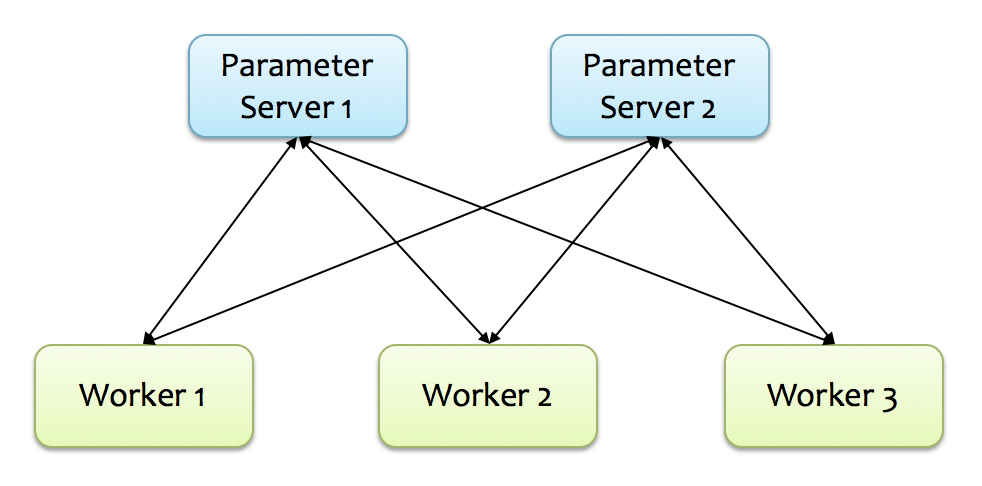
对于PS架构,Parameter Server的Task集合为ps(即job类型为ps),而执行梯度计算的Task集合为worker(即job类型为worker),所以一个TensorFlow Cluster可以通过如下json描述:1
2
3
4
5
6
7
8
9
10
11{
"worker": [
"${host1}:${port1}",
"${host2}:${port2}",
"${host3}:${port3}"
],
"ps": [
"${host4}:${port4}",
"${host5}:${port5}"
]
}
Low-level 分布式编程模型
最原始的分布式TensorFlow编程是基于Low-level API来实现,下面我们通过举例来理解最原始的分布式TensorFlow编程步骤。我们在一台机器上启动三个Server(2个worker,1个ps)来模拟分布式多机环境,开启三个Python解释器(分别对应2个worker和1个ps),执行如下python语句,定义一个Cluster:1
2
3
4
5
6
7
8
9
10import tensorflow as tf
cluster = tf.train.ClusterSpec({
"worker": [
"localhost:2222",
"localhost:2223"
],
"ps": [
"localhost:2224"
]})
在第一个worker解释器内执行如下语句启动Server:1
server = tf.train.Server(cluster, job_name="worker", task_index=0)
在第二个worker解释器内执行如下语句启动Server:1
server = tf.train.Server(cluster, job_name="worker", task_index=1)
在ps解释器内执行如下语句启动Server:1
server = tf.train.Server(cluster, job_name="ps", task_index=0)
至此,我们已经启动了一个TensorFlow Cluster,它由两个worker节点和一个ps节点组成,每个节点上都有Master Service和Worker Service,其中worker节点上的Worker Service将负责梯度运算,ps节点上的Worker Service将负责参数更新,三个Master Service将仅有一个会在需要时被用到,负责子图划分与Task派发。
有了Cluster,我们就可以编写Client,构建计算图,并提交到这个Cluster上执行。使用分布式TensorFlow时,最常采用的分布式训练策略是数据并行,数据并行就是在很多设备上放置相同的模型,在TensorFlow中称之为Replicated training,主要表现为两种模式:图内复制(in-graph replication)和图间复制(between-graph replication)。不同的运行模式,Client的表现形式不一样。
图内复制
对于图内复制,只构建一个Client,这个Client构建一个Graph,Graph中包含一套模型参数,放置在ps上,同时Graph中包含模型计算部分的多个副本,每个副本都放置在一个worker上,这样多个worker可以同时训练复制的模型。
再开一个Python解释器,作为Client,执行如下语句构建计算图,并:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17import tensorflow as tf
with tf.device("/job:ps/task:0"):
w = tf.get_variable([[1., 2., 3.], [1., 3., 5.]])
input_data = ...
inputs = tf.split(input_data, num_workers)
outputs = []
for i in range(num_workers):
with tf.device("/job:ps/task:%s" % str(i)):
outputs.append(tf.matmul(inputs[i], w))
output = tf.concat(outputs, axis=0)
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
print sess.run(output)
从以上代码可以看到,当采用图内复制时,需要在Client上创建一个包含所有worker副本的流程图,随着worker数量的增长,计算图将会变得非常大,不利于计算图的维护。此外,数据分发在Client单点,要把训练数据分发到不同的机器上,会严重影响并发训练速度。所以在大规模分布式多机训练情况下,一般不会采用图内复制的模式,该模式常用于单机多卡情况下,简单直接。
图间复制
为可以解决图内复制在扩展上的局限性,我们可以采用图间复制模式。对于图间复制,每个worker节点上都创建一个Client,各个Client构建相同的Graph,但是参数还是放置在ps上,每个worker节点单独运算,一个worker节点挂掉了,系统还可以继续跑。
所以我们在第一个worker和第二个worker的Python解释器里继续执行如下语句实现Client完成整个分布式TensorFlow的运行:1
2
3
4
5
6
7
8
9
10
11
12
13with tf.device("/job:ps/task:0"):
w = tf.get_variable(name='w', shape=[784, 10])
b = tf.get_variable(name='b', shape=[10])
x = tf.placeholder(tf.float32, shape=[None, 784])
y = tf.placeholder(tf.int32, shape=[None])
logits = tf.matmul(x, w) + b
loss = ...
train_op = ...
with tf.Session() as sess:
for _ in range(10000):
sess.run(train_op, feed_dict=...)
在上述描述的过程中,我们是全程手动做分布式驱动的,先建立Cluster,然后构建计算图提交执行,Server上的Master Service和Worker Service根本没有用到。实际应用时当然不会这么愚蠢,一般是将以上代码片段放到一个文件中,通过参数控制执行不同的代码片段,例如:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24import tensorflow as tf
ps_hosts = FLAGS.ps_hosts.split(",")
worker_hosts = FLAGS.worker_hosts.split(",")
cluster = tf.train.ClusterSpec({"ps": ps_hosts, "worker": worker_hosts})
server = tf.train.Server(
cluster, job_name=FLAGS.job_name, task_index=FLAGS.task_index)
if FLAGS.job_name == 'ps':
server.join()
elif FLAGS.job_name == "worker":
with tf.device(tf.train.replica_device_setter(
worker_device="/job:worker/task:%d" % FLAGS.task_index,
cluster=cluster)):
# Build model...
loss = ...
train_op = ...
with tf.train.MonitoredTrainingSession(
master="/job:worker/task:0",
is_chief=(FLAGS.task_index == 0),
checkpoint_dir="/tmp/train_logs") as mon_sess:
while not mon_sess.should_stop():
mon_sess.run(train_op)
每个节点上都执行如上代码,只是不同节点输入的参数不一样,对于ps节点,启动Server后就堵塞等待参数服务,对于worker节点,启动Server后(后台服务),开始扮演Client,构建计算图,最后通过Session提交计算。注意在调用Session.run之前,仅仅是Client的构图,并未开始计算,各节点上的Server还未发挥作用,只有在调用Session.run后,worker和ps节点才会被派发Task。在调用Session.run时,需要给Session传递target参数,指定使用哪个worker节点上的Master Service,Client将构建的计算图发给target指定的Master Service,一个TensorFlow集群中只有一个Master Service在工作,它负责子图划分、Task的分发以及模型保存与恢复等,在子图划分时,它会自动将模型参数分发到ps节点,将梯度计算分发到worker节点。另外,在Client构图时通过tf.train.replica_device_setter告诉worker节点默认在本机分配Op,这样每个Worker Service收到计算任务后构建出一个单独的计算子图副本,这样每个worker节点就可以单独运行,挂了不影响其他worker节点继续运行。
虽然图间复制具有较好的扩展性,但是从以上代码可以看到,写一个分布式TensorFlow应用,需要用户自行控制不同组件的运行,这就需要用户对TensorFlow的分布式架构有较深的理解。另外,分布式TensorFlow应用与单机版TensorFlow应用的代码是两套,一般使用过程中,用户都是先在单机上调试好基本逻辑,然后再部署到集群,在部署分布式TensorFlow应用前,就需要将前面的单机版代码改写成分布式多机版,用户体验非常差。所以说,使用Low-level 分布式编程模型,不能做到一套代码既可以在单机上运行也可以在分布式多机上运行,其用户门槛较高,一度被相关工程及研究人员诟病。为此,TensorFlow推出了High-level分布式编程模型,极大地改善用户易用性。
High-level 分布式编程模型
TensorFlow提供Estimator和Dataset高阶API,简化模型构建以及数据输入,用户通过Estimator和Dataset高阶API编写TensorFlow应用,不用了解TensorFlow内部实现细节,只需关注模型本身即可。
Estimator代表一个完整的模型,它提供方法用于模型的训练、评估、预测及导出。下图概括了Estimator的所有功能。
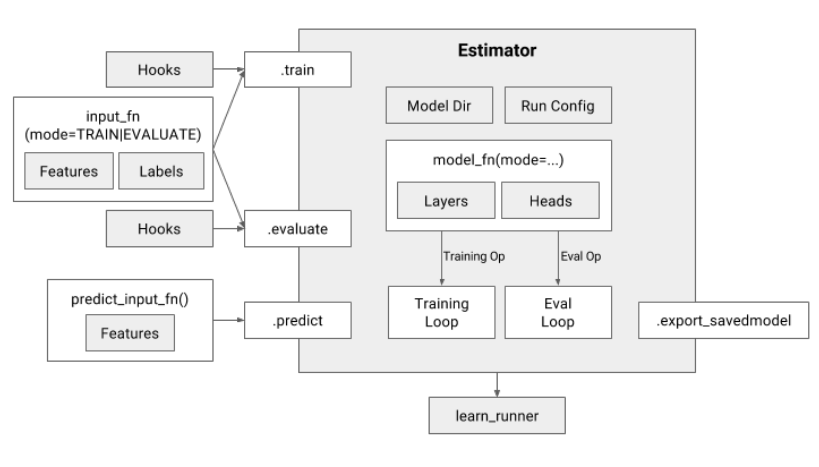
Estimator具备如下优势:
- 基于Estimator编写的代码,可运行在单机和分布式环境中,不用区别对待
- 简化了模型开发者之间共享部署,它提供了标准的模型导出功能,可以将训练好的模型直接用于TensorFlow-Serving等在线服务
- 提供全套的分布式训练生命周期管理,自动初始化变量、处理异常、创建检查点文件并从故障中恢复、以及保存TensorBoard 的摘要等
- 提供了一系列开箱即用的常见
Estimator,例如DNNClassifier,LinearClassifier等
使用Estimator编写应用时,需将数据输入从模型中分离出来。数据输入可以通过 Dataset API 构建数据 pipeline,类似Spark RDD或DataFrame,可以轻松处理大规模数据、不同的数据格式以及复杂的转换等。具体关于Estimator的使用可以参考TensorFlow官方文档,讲的特别详细。
使用Estimator编写完应用后,可以直接单机上运行,如果需要将其部署到分布式环境运行,则需要在每个节点执行代码前设置集群的TF_CONFIG环境变量(实际应用时通常借助资源调度平台自动完成,如K8S,不需要修改TensorFlow应用程序代码):1
2
3
4
5
6
7
8TF_CONFIG='{
"cluster": {
"chief": ["host0:2222"],
"worker": ["host1:2222", "host2:2222", "host3:2222"],
"ps": ["host4:2222", "host5:2222"]
},
"task": {"type": "chief", "index": 0}
}'
TF_CONFIG环境变量是一个json字符串,指定集群规格cluster以及节点自身的角色task,cluster包括chief、worker、ps节点,chief节点其实是一个特殊的worker节点,而且只能有一个节点,表示分布式TensorFlow Master Service所在的节点。
通过以上描述可以看到,使用高阶API编写分布式TensorFlow应用已经很方便了,然而因为PS架构的缘故,我们实际部署时,需要规划使用多少个ps,多少个worker,那么调试过程中,需要反复调整ps和worker的数量。当模型规模较大时,在分布式训练过程中,ps可能成为网络瓶颈,因为所有worker都需要从ps处更新/获取参数,如果ps节点网络被打满,那么worker节点可能就会堵塞等待,以至于其计算能力就发挥不出来。所以后面TensorFlow引入All-Reduce架构解决这类问题。
基于All-Reduce的分布式TensorFlow架构
在单机多卡情况下,如下图左表所示(对应TensorFlow图内复制模式),GPU1~4卡负责网络参数的训练,每个卡上都布置了相同的深度学习网络,每个卡都分配到不同的数据的minibatch。每张卡训练结束后将网络参数同步到GPU0,也就是Reducer这张卡上,然后再求参数变换的平均下发到每张计算卡。
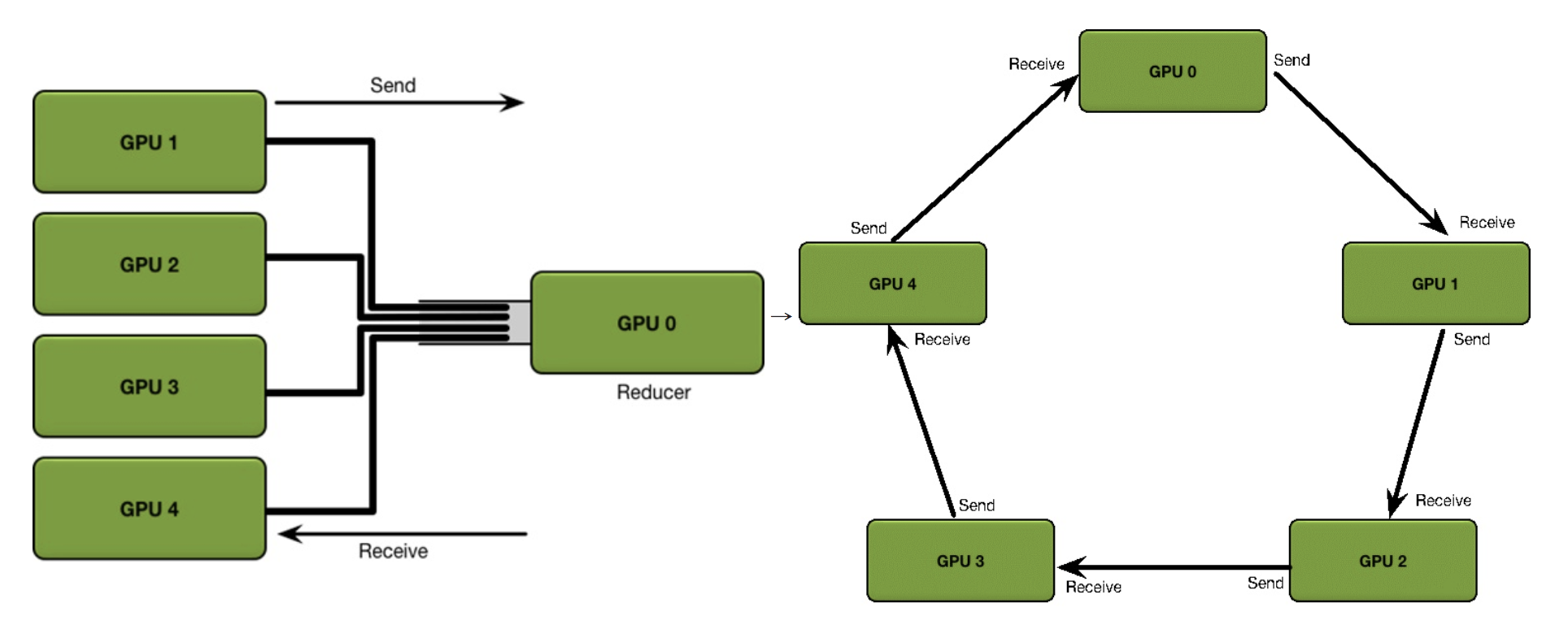
很显然,如果GPU较多,GPU0这张卡将成为整个训练的瓶颈,为了解决这样的问题,就引入了一种通信算法Ring Allreduce,通过将GPU卡的通信模式拼接成一个环形,解决带宽瓶颈问题,如上图右边所示。Ring Allreduce最早由百度提出,通过Ring Allreduce算法可以将整个训练过程中的带宽占用分摊到每块GPU卡上,详情可参考uber的一篇论文。
TensorFlow从v1.8版本开始支持All-Reduce架构,它采用NVIDIA NCCL作为All-Reduce实现,为支持多种分布式架构,TensorFlow引入Distributed Strategy API,用户通过该API控制使用何种分布式架构,例如如果用户需要在单机多卡环境中使用All-Reduce架构,只需定义对应架构下的Strategy,指定Estimator的config参数即可:1
2
3
4
5
6
7mirrored_strategy = tf.distribute.MirroredStrategy()
config = tf.estimator.RunConfig(
train_distribute=mirrored_strategy, eval_distribute=mirrored_strategy)
regressor = tf.estimator.LinearRegressor(
feature_columns=[tf.feature_column.numeric_column('feats')],
optimizer='SGD',
config=config)
对于分布式多机环境,最早是Uber专门提出了一种基于Ring-Allreduce的分布式TensorFlow架构Horovod,并已开源。目前TensorFlow已经官方支持,通过MultiWorkerMirroredStrategy来指定,目前该API尚处于实验阶段。如果在代码中通过MultiWorkerMirroredStrategy指定使用All-Reduce架构,则分布式提交时,TF_CONFIG环境变量中的cluster就不需要ps类型的节点了,例如:1
2
3
4
5
6
7TF_CONFIG='{
"cluster": {
"chief": ["host0:2222"],
"worker": ["host1:2222", "host2:2222", "host3:2222"]
},
"task": {"type": "chief", "index": 0}
}'
通过不同的Strategy,可以轻松控制使用不同的分布式TensorFlow架构,可见TensorFlow的API设计更加灵活友好,拥有极强的可扩展性,相信将来会出现更多的Strategy来应对复杂的分布式场景。
小结
本文梳理了分布式TensorFlow编程模型的发展,主要从用户使用分布式TensorFlow角度出发,阐述了不同的分布式TensorFlow架构。可以看到,随着TensorFlow的迭代演进,其易用性越来越友好。目前TensorFlow已经发布了2.0.0-alpha版本了,标志着TensorFlow正式进入2.0时代了,在2.0版本中,其主打卖点是Eager Execution与Keras高阶API,整体易用性将进一步提升,通过Eager Execution功能,我们可以像使用原生Python一样操作Tensor,而不需要像以前一样需要通过Session.run的方式求解Tensor,另外,通过TensorFlow Keras高阶API,可以更加灵活方便构建模型,同时可以将模型导出为Keras标准格式HDF5,以灵活兼容在线服务等。
转载请注明出处,本文永久链接:https://sharkdtu.github.io/posts/dist-tf-evolution.html

